
В предыдущем занятии мы загрузили данные и трансформировали их формат в вид, пригодный для дальнейшего обогащения. Однако, чтобы лучше ориентироваться в этих данных, есть смысл разбить их на группы, по которым будет выстраиваться дальнейшая классификация клиентов.
Важно! Если вы не ознакомлены с темой предыдущего дня «Заправляем сценарий клиентской матрицей. Подготовка данных», то для большего понимания советуем предварительно прочитать этот материал.
Узлы второй группы (обогащение) позволяют создать новые аналитические признаки в данных, с помощью которых легко выявлять необходимые сценарии. Давайте добавим эти узлы в сценарий.
Так как эти узлы настроены на получение данных из компонента подготовки данных, то настраивать сопоставление полей не надо. Однако, почему мы используем целых 3 узла вместо одного?
Как вы могли заметить, узлы разграничены по типам рассчитываемых признаков. Такая структура хорошо отображает составляющие процесса для бизнес-пользователя. А также позволяет обратиться к отдельным видам сегментации без создания ненужных в моменте столбцов.
Какие разрезы идут в сегментацию?
Прежде всего, мы должны понимать, что означает клиент с точки зрения финансов для компании. Для этого используются 3 основных показателя:
Однако, анализировать голые цифры нет смысла. Для удобства их нужно разбить на группы, за это отвечает входной порт переменных.
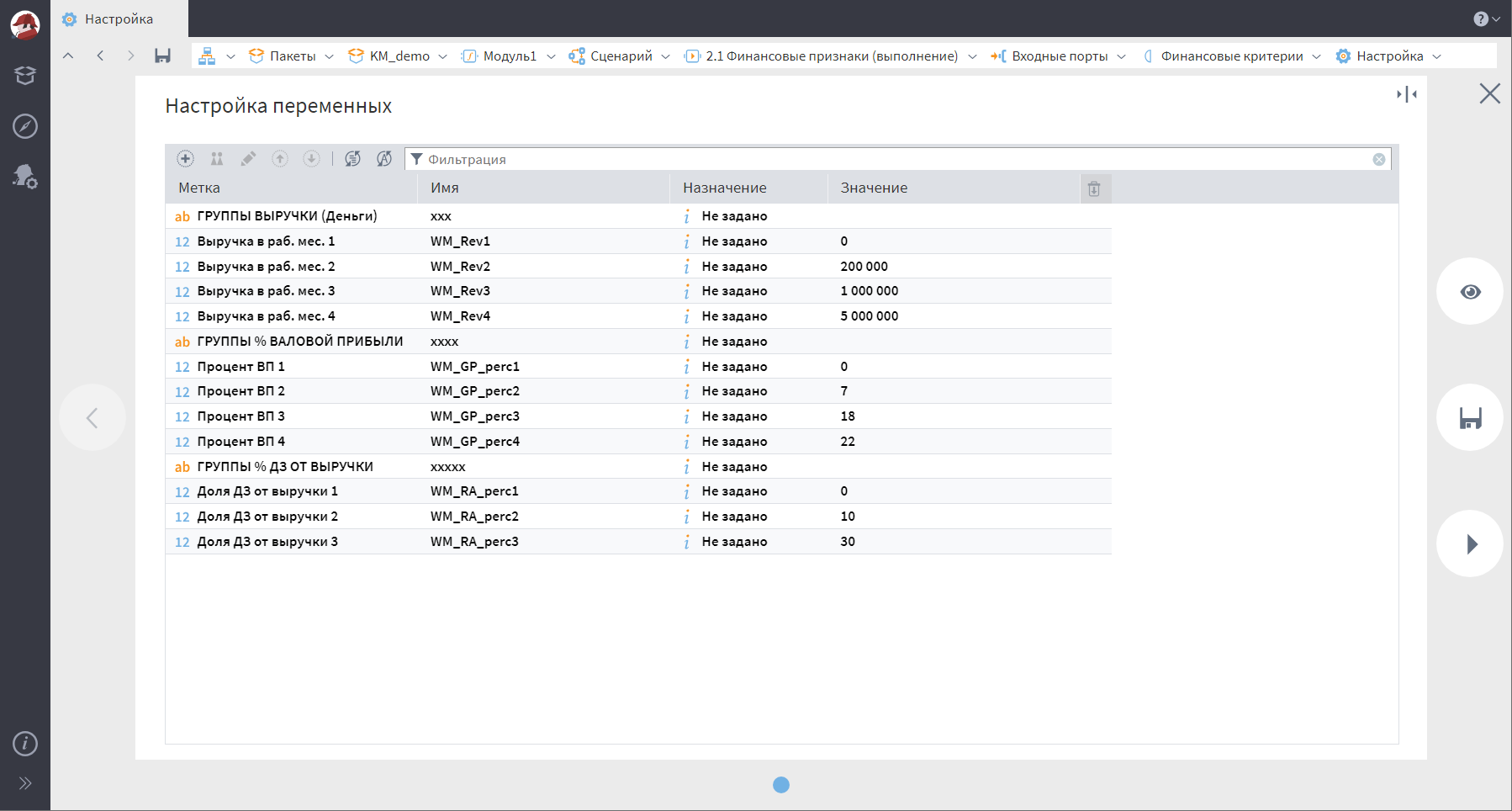
А вот кстати и еще одна причина разнесения бизнес-логики на отдельные модули. Когда настроек очень много, есть смысл размещать их в разных портах или модулях, чтобы не перегружать пользователей.
Кстати, если наборы переменных представляют из себя группы, их можно разделять фейковыми переменными, которые не используются в расчетах, но облегчают восприятие настроек.
Как определять диапазоны разбивки для вашего бизнеса, рассказано в конце статьи.
Использование этих настроек позволяет разбить показатели на группы, а именно:
Один из ключевых моментов анализа клиентских сегментов — это понимание их динамики. А именно как они меняются по сравнению с прошлым месяцем. Поэтому мы вытаскиваем в каждую строку классы клиентов из прошлых месяцев:
Чтобы упростить исследование негативной и позитивной динамики, мы также считаем количество позиций, на которые изменился класс. Положительные значения — значит позитивная динамика:
Так, если у клиента был класс ДЗ«4. Больше 30%», а стал «2. Больше 0 %, но меньше или равно 10%», то динамика класса ДЗ у него будет 2. В то же время, если его выручка была «1. Меньше или равно 0», и стала «3. Больше 200 000, но меньше или равно 1 000 000», то динамика класса Выручка также будет 2.
Обогащение данных требуется для сокращения рутинных действий пользователем, позволяя ему в одно действие находить данные, поиск которых в исходном наборе потребовал бы множества сложных телодвижений. Или даже вообще был бы невозможен.
Тут у нас все по аналогии с выручкой, только про объем проданной продукции:
Это большой набор показателей, который определяет частоту покупок клиента, стабильность графика закупок, сигнализирует об отклонениях, а также вводит классификацию давности работы клиента с компанией.
Отметки «_В» в некоторых статусах значат «вернулся». Такой клиент дошел однажды до состояния «Потерянный» и хуже, но в итоге вернулся в рабочий режим. Для таких случаев нужны отдельные бизнес-процессы работы.
Подробнее обо всех комбинациях мы расскажем в следующем дне:

Руководитель и архитектор self-service решений BI2BUSINESS
Что касается правил построения компонентов для сложных сценариев, сегодня мы узнали, что:

Когда вы собираетесь проранжировать группу каких-то объектов (например клиентов), то хорошо привести их единой базе, так сказать. Ключевая ценность клиента — приносимые им выручка и прибыль. Однако при прямом сравнении этих показателей старые клиенты всегда будут превосходить новых. Даже если новые клиенты имеют хороший потенциал по сравнении со старыми.
Поэтому вместо сравнения общей суммы продаж, мы сравниваем клиентов по средней выручке за рабочий месяц (месяц, когда клиент отгружался за период последних 12 месяцев).
Таким образом, в оценку попадают только продажи последнего года. Вы можете сказать: «но постойте, получается, что клиент, купивший раз в год на 100 000, по этому показателю будет равен клиенту, который каждый месяц покупает на 100 000».
И это правильный вопрос. Но для уточнения значимости данного класса выручки у нас будут уточняющие параметры в частотно-временных признаках. Именно эти признаки будут определять текущий сценарий работы с клиентом, и они завязаны на периодичность покупок и стабильность спроса.
Поэтому в итоге редко покупающий клиент на среднюю сумму в 100 000 в месяц не будет равен часто покупающему клиенту на аналогичную сумму.
Но о том, как интерпретировать эти сегменты, мы поговорим завтра. А сегодня разберем еще один вопрос.
Рассмотрим на примере классификации выручки. Сейчас клиенты разбиваются на группы:
Понять, на какие группы разбивать клиентов в вашем случае? Эта работа делается в 2 захода. Первым делом нужно понять, делится ли у вас клиентская база на направления бизнеса. Например, опт и розницу. Нет смысла анализировать разные направления продаж вместе. У них разный бизнес-процесс, разные нормы прибыли и оборотов.
Дальше, взяв отдельные направления, спрашиваем коммерческого директора: «Какая среднемесячная выручка по клиенту считается прямо супер-хорошей?». Это будет значение для самого верхнего уровня, т.е. 5 000 000. Далее спрашиваем: «А какой уровень выручки будет по клиентам на ступень меньше?». И так определяем все уровни сверху вниз.
Почему действуем именно так, а не высчитываем сегменты сами через какие-либо алгоритмы? Потому что нам важно синхронизировать границы сегментации с видением руководства. Будет ли такая оценка точна? Может быть, да, а может быть, нет. Но она служит отправной точкой. После вы сможете наложить эти сегменты на график продаж и продемонстрировать реальное распределение выручки по этим группам. И может так оказаться, что группа «5. больше 5 000 000» приносит условно 10 млн. в месяц. А группа «3. больше 200 000, но меньше или равно 1 000 000» — 25 млн. в месяц. А значит, более важными являются именно клиенты группы 3, и ее надо выносить как главную. «5. больше 5 000 000» могут быть исключены из сегментации как клиенты другого направления продаж.
Таким образом, вы постепенно сближаетесь в своих оценках с руководством компании и корректируете их на основе общего согласия. С остальными параметрами поступаем аналогично.
