
Конечно, ABC-анализ — довольно простая задача и легко решается созданием одного-единственного блока. Но что делать с более сложными сценариями?
Очевидно, механика производных компонентов позволяет упаковать в них схемы любой сложности. Потребность в этом возникает при переносе в Loginom различных многоуровневых процессов. Например, сегментации клиентской базы, с примером которой мы будем работать дальше.
Важно! Если вы не ознакомлены с темой предыдущего дня «Шинкуем эталонный data-салат. Рецепт сборки собственных компонентов», то для большего понимания советуем предварительно прочитать этот материал.
Такие процессы могут требовать несколько входных таблиц, а также обширные настройки. Должны ли мы стремиться упаковать весь процесс в один единственный компонент, который будет делать сразу все?
Конечно же, нет. Хотя технически мы никак не ограничены по количеству входов и выходов в узлах (кроме разумных пределов), не стоит многоступенчатый процесс упаковывать в один единственный модуль.
На то есть несколько причин:
Давайте посмотрим, как это можно организовать на примере коммерческой библиотеки сегментации клиентов в B2B-продажах.
Скачайте в удобное место на жестком диске и распакуйте архив с библиотекой компонентов «Клиентская матрица».
У вас получится такой набор файлов:
Вы не сможете открыть пакет Клиентская матрица.lgp, т.к. он является зашифрованным. Однако при указании ссылки на этот пакет его производные компоненты становятся доступными для использования в ваших сценариях.
Для шифрования собственных пакетов можно воспользоваться готовым сервисом, позволяющим выполнить эту операцию за несколько кликов.
Создайте новый пакет «KM_demo». Можно прямо в папке с клиентской матрицей. Добавьте в нем ссылку на пакет «Клиентская матрица». Убедитесь, что в разделе «Производные компоненты» появился список модулей решения.
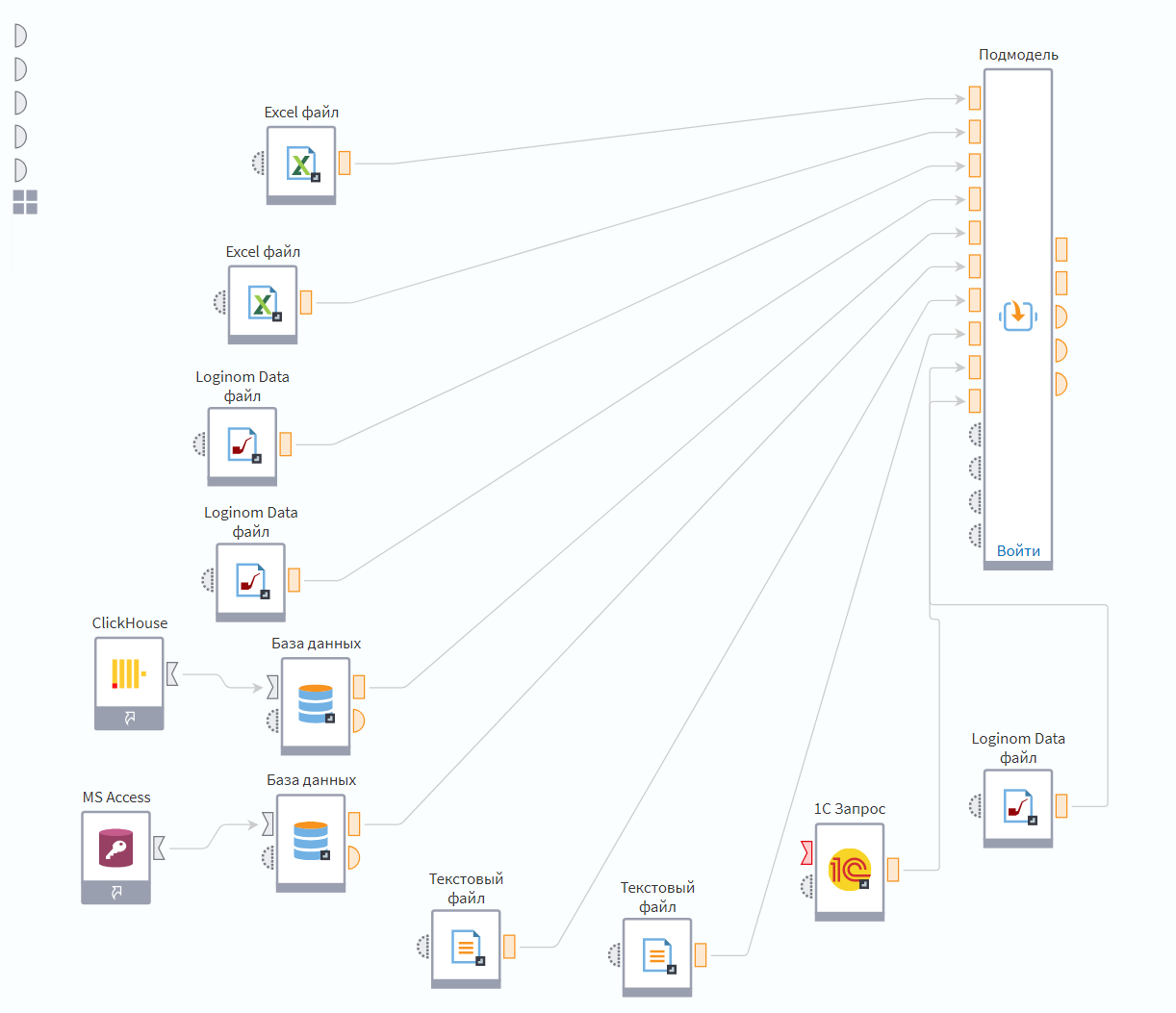
Забегая немного вперед, скажу, что итоговая схема будет выглядеть вот так:
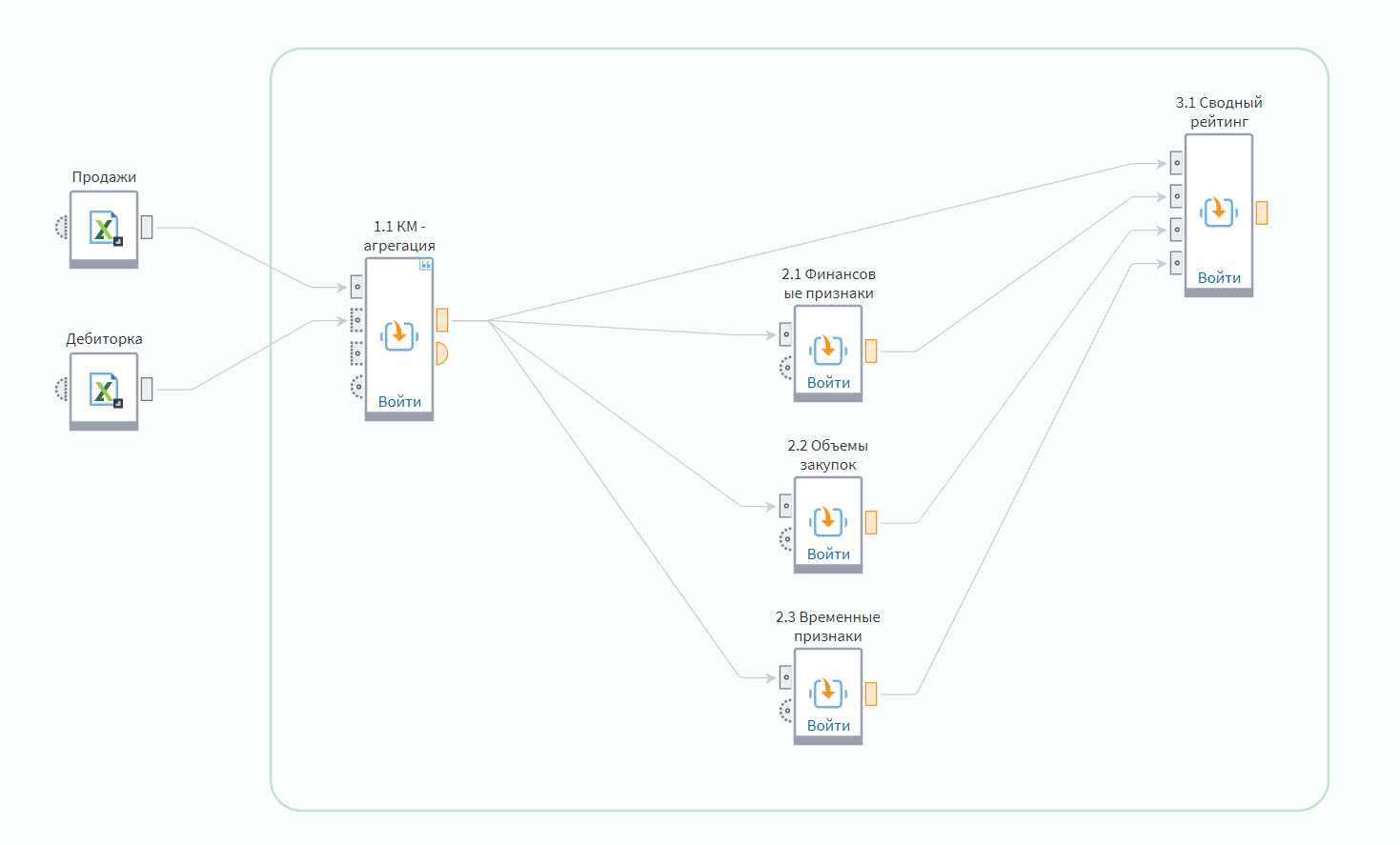
Зеленой рамкой обведены компоненты «Клиентской матрицы». Мы будем работать с двумя таблицами исходных данных: транзакций и дебиторской задолженности клиентов на конец месяца. А дальше идет их последовательная обработка.
Узел 1.1 трансформирует данные в формат, удобный для дальнейшей обработки. Узлы 2.1, 2.2, 2.3 рассчитывают аналитические признаки по 3-м наборам критериев. Узел 3.1 консолидирует ранее обогащенные данные и присваивает клиенту один из 17 рабочих сценариев — рекомендацию, что именно с ним делать дальше.
В целом для сложных бизнес-сценариев обычно можно выделить 3 вида узлов:
Вы можете проектировать свои библиотеки аналогичным образом и быть уверенными, что обеспечите удобную модульность решения для себя, и прозрачный процесс работы для бизнес-пользователей.
Основная идея «Клиентской матрицы» — выстроить на каждый месяц состояние клиентской базы с глубиной на 12 месяцев назад. Сравнивая динамику состояния клиентов, а также оценивая их значимость с точки зрения финансов, объемов, регулярности отгрузок и срока жизни, каждому клиенту определяется один из 17 рабочих сценариев.
А мы сделаем первый шаг — подадим данные на трансформацию. Напомним, мы используем стандартную транзакционную таблицу продаж, а также таблицу дебиторской задолженности в разрезе клиентов. Демонстрационные данные содержатся в excel-таблицах в папке библиотеки компонентов.
Т.к. файлы заранее подготовленные, сопоставление полей в портах произойдет автоматически. Если будете использовать собственные данные, то нужно будет сопоставить вручную.
Мы не будем использовать третий порт данных, но обозначим: в него можно подать таблицу с датами первых продаж клиента. Это нужно для более точного определения возраста клиента. Например, если эта таблица не подается на вход, то дата первой покупки рассчитывается как минимальная дата покупки. Как именно это организовано — разобрали в прямом эфире, который доступен после регистрации ниже.
У узла «1.1 КМ — агрегация» есть одна особенность — он работает в демо-режиме. Если подать на первый вход данные из демо-файла, то они отрабатываются в полном объеме. Если вы подадите туда ваши данные — то сегментация подготовится по 10% клиентов, но не более чем по 100 уникальным клиентам. Как это сделано — тоже разбираем на эфире.
Обратите внимание — на выходе, помимо порта данных, есть порт переменных. В него выводится сообщение, в каком режиме демонстрации отработал узел. Полезно делать такие выходы с диагностическими сообщениями, чтобы информировать пользователя о том, что происходит внутри и есть ли какие-нибудь инциденты.
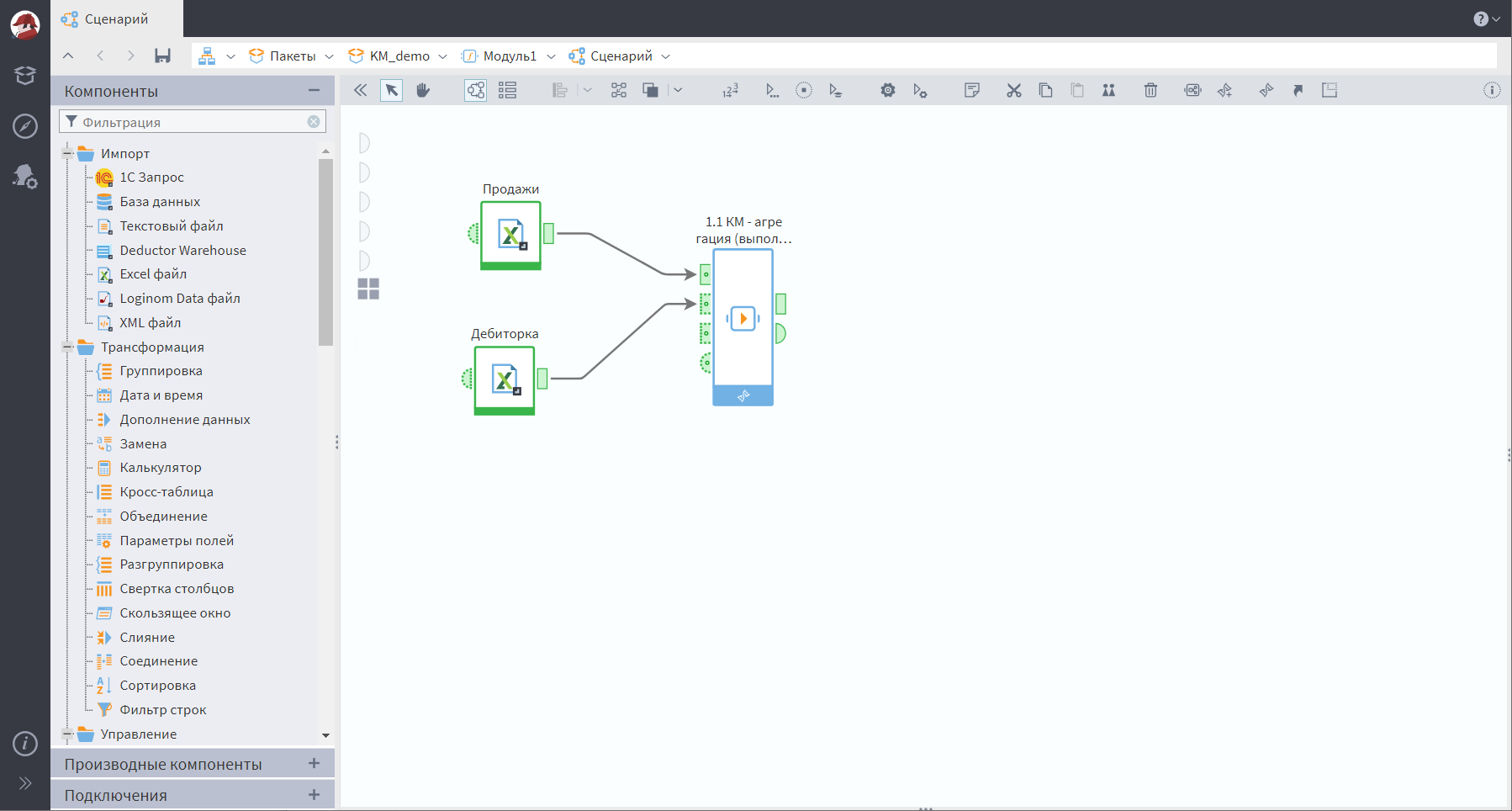
На этом завершим сегодняшнее занятие, т.к. после подготовки данных мы имеем следующий результат.
По каждому клиенту на каждый месяц формируется перечень следующих показателей на основе его статистики за 12 месяцев от месяца сегментации:
Пока это только ничего не значащие цифры. Но это изменится в последующих днях, после того как мы перейдем к обогащению данных.
Попробуйте изменить набор данных по продажам. Например, поставив фильтр перед вводом в первый порт. Если компонент «не узнает» входную таблицу, то он переключится в режим «считать 10% клиентов, но не более чем по 100 уникальным клиентам». В выходной переменной можете понять, что переключение произошло.

Что делать, если руководитель компании (ваш руководитель) саботирует внедрение аналитических инструментов? Директор говорит: «я управляю, глядя на три цифры, у меня такая чуйка, что никакая аналитика не нужна». Ну и прочий скепсис по поводу использования инструментов аналитики.
По опыту Юлии хорошо работают следующие аргументы:
Принимать решения, опираясь на три показателя — хорошо. Но для правильных решений нужна возможность разложить 3 показателя на 15-20-25 в зависимости от нюансов принимаемых решений. Иначе можно упустить суть вопроса и принять неверное решение. Вы можете упустить возможности роста бизнеса, оперируя только общими цифрами.
Например, у компании есть поток клиентов, и часть из них считается нецелевыми, потому что отдел продаж заточен на крупный опт, и им не хочется возиться с «малышами». Но если сегмент небольших клиентов достаточно объемен, то можно пускать их по отдельному автоматизированному сценарию обслуживания и получить таким образом или новое направление бизнеса, или вообще отдельный бизнес. Такие вещи нельзя обнаружить, глядя на ситуацию только верхнеуровнево.
Чуйка — это очень хорошо, но она есть не у всех и нарабатывается годами ведения бизнеса. Нельзя масштабировать чуйку на большой коллектив. Большому коллективу нужна система и понятные правила управления. Это может дать только глубокая система аналитики. Пока все находятся в одном помещении, руководитель «на чуйке» может справляться с управлением.
Когда речь идет о структуре с десятками и сотнями сотрудников, распределенных по филиалам — только выстроенная система анализа с прописанными сценариями «случилось X — делаем Y» может устойчиво работать и развиваться. Нужно строить конвейер управления, на который легко запускать новых людей и легко их заменять при необходимости.
Дополнительно стоит учитывать, что, принимая решения, мы отталкиваемся от предположения, то данные верны, даже если это не говорится явно. Это часто принимается как нечто само собой разумеющееся. Как, например, то, что при покупке машины у нее будут фары. Однако реальность такова, что в самих данных могут быть ложная информация. Из-за ошибок, проблем с заполнениями, неправильными форматами и т.д. И найти такое можно только с помощью инструментов глубокой аналитики.
Если подытожить, то аналитика — это инструмент поддержки роста бизнеса за счет 4-х факторов:
Определите, какой путь наиболее актуален в вашей ситуации, и используйте соответствующие аргументы.
