
Давайте разберемся, в каких случаях нужно использовать функционал производных компонентов.
Важно! Если вы не ознакомлены с темой предыдущего дня «Начинаем гастрономическое путешествие. Преимущества переиспользования компонентов», то для большего понимания советуем предварительно прочитать этот материал.
Скачайте архив ниже и распакуйте его в любом месте на жестком диске. Откройте скачанный пакет с помощью Loginom. Вы обнаружите в нем сценарий, рассчитывающий варианты ABC-анализа: по клиентам и по товарам.
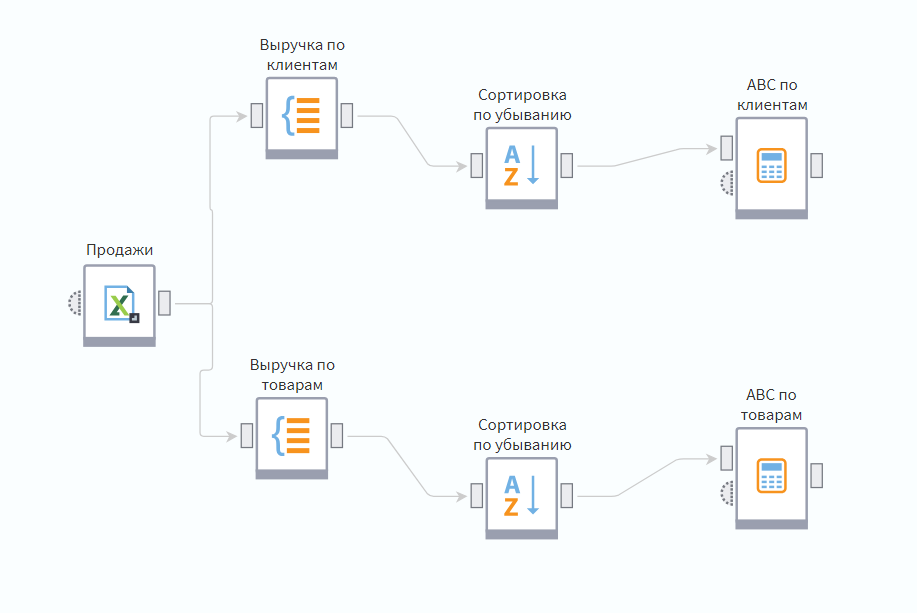
Каждая ветка реализует один и тот же сценарий, только с разным разрезом: верхняя делает сегментацию по клиентам, а нижняя — по товарам.
В моменте схема работает нормально. Но что делать, если нам потребуется сделать ABC-анализ в других разрезах? Будем плодить ветки? А если нужно будет использовать этот функционал в разных пакетах?
Конечно, можно свернуть ветки в подмодели, и копировать их станет удобнее даже между проектами.
Но внутри подмоделей по-прежнему будут находиться независимые узлы. А что, если потом вам нужно будет дополнить этот функционал? Представляете, как приходится искать все копии алгоритма и менять его?
Требуется выполнять одну и ту же последовательность действий в нескольких местах, и отличия заключаются только в параметрах и наборах данных? Значит, настало время производных компонентов!
Основная фишка производных компонентов — их можно переиспользовать в разных местах сценария. При этом их источником является одна схема обработки данных, изменив которую, вы автоматически измените ее во всех используемых местах. Еще производные компоненты не обязательно должны находиться физически в том пакете, где вы их хотите использовать. Их можно держать в отдельных пакетах и подключать как библиотеки.
Поэтому для начала давайте создадим новый пакет в той же папке, где располагается наш текущий учебный пакет.
Перейдем на вкладку с учебным пакетом, скопируем в нем одну из веток ABC-анализа и вставим в новый пакет.
Кстати, если мы попробуем выполнить этот сценарий, то получим ошибку по очевидной причине: узел группировки ждет на вход данные, а их нет.

Добавлять ли сюда источник данных? Обойдемся без него! Loginom настолько самодостаточная система, что ему не нужны данные для проектирования сценариев. Давайте приведем наш сценарий к универсальному переиспользуемому виду.
Чтобы переиспользовать сценарии из нескольких узлов (у нас 3 узла в сценарии), нужно поместить их в подмодель. Это можно сделать, выделив цепочку узлов и нажав соответствующую кнопку в верхней панели или контекстном меню, вызываемом ПКМ.
Если промахнулись и свернули в подмодель не все желаемые узлы, то подмодель можно развернуть обратно той же кнопкой и уже повторно захватить все, что нужно. Назовем нашу модель «ABC анализ».
Однако сейчас наша подмодель — как избушка без окон и дверей. Чтобы от нее был толк, данные должны иметь возможность попасть в нее через входные порты, и «выбраться» через выходные.

Создайте входные и выходные порты для подмодели. Входной порт сделайте необязательным. Зачем? Это поможет нам в проектировании, скоро увидите, как.
Рекомендуется давать портам «человекопонятные» названия. Даже модели с единичными входами/выходами выглядят так намного профессиональнее. Тем более что название порта всплывает, если навести мышь на порт. В сложных моделях с большим количеством входов и выходов это является обязательным условиям, чтобы пользователь понимал, что от него ждут.
Порты появились. Входной порт обведен пунктиром, потому что он необязательный. Выходной порт светится красным, потому что изнутри подмодели на него не подается никаких данных и не отключена автосинхронизация на нем.
Но не будем торопиться с внутренними настройками подмодели. Поработаем еще немного над входом. Дело в том, что по умолчанию порты работают в режиме автосинхронизации. Т.е. все данные, которые заходят в порт — проходят дальше. Это не очень удобно в производных компонентах, потому что для работы сценария нужен только набор полей (для нашего ABC-анализа: Разрез (Клиент, Товар и т.д.) и показатель (Выручка, прибыль и так далее)). Все остальные поля будут только захламлять нам настройки узлов.
Но помимо этой проблемы, есть еще одна — сопоставление полей, которые используются в сценарии с полями, которые подаются на вход. Например, вы создали подмодель, которая работает с полем Client_ID. А пользователь подает на вход поле Identifikator_Klienta.
Сама по себе подмодель, конечно же, не поймет, что нужные данные лежат в другом поле. И выполнение сценария окончится ошибкой.
Чтобы этого не происходило, нужно на входном порте создать перечень ожидаемых полей, которые будут использоваться в подмодели. А также отключить автосинхронизацию, чтобы лишние поля не циркулировали внутри. Это делается через настройки порта.
Таким образом, мы можем управлять пониманием пользователя относительно того, какие данные нужно подавать на вход, и не даем ему совершить ошибок.
Создадим 2 поля, с которыми будем работать. Пусть первое будет строковым и называется ABC сегмент. А второе пусть будет вещественным и называется ABC показатель. Также не забываем отключить автосинхронизацию, отжав квадратик с буквой A.
Теперь наша подмодель выглядит так. На входном порту появился кружочек. Это значит, что автосинхронизация отключена, и подмодель пропускает внутрь только те поля, которые заданы в настройках порта.

Ныряем внутрь! Теперь мы можем пожинать плоды от того, что сделали входной порт необязательным. Если активировать необязательный входной порт с заданными полями, то из него выйдет пустая таблица с этими полями, но без данных.
Такую пустую таблицу можно использовать, чтобы прогнать ее через сценарий, не загружая данные. Что отлично подходит для быстрой разработки сценариев с уже заранее понятной вам структурой.
Займемся адаптацией нашего сценария к новому входу. Протянем связь от входного порта к узлу группировки. Вход группировки сразу загорелся красным. Почему же? Дело в том, что этот узел уже настроен под набор полей из первоначального сценария. И, не обнаружив их на входе, сигналит об этом.
Любое поле, которое используется внутри узла, является обязательным для входа. Нам эти старые поля не нужны, поэтому, зайдя в настройки узла, просто удалим их, устранив таким образом конфликт. А дальше уже в настройках группировки установим наши новые универсальные поля, которые тянутся от входа в подмодель.
Аналогичным образом настроим сортировку. Нам нужно, чтобы она сортировала таблицу по убыванию показателя ABC.
Финальный штрих — перенастраиваем калькулятор. В первых 2-х формулах (итоговая сумма ABC-показателя и сумма ABC-показателя накопительным итогом) нужно заменить название поля Revenue на ABC-показатель.
На этом с калькулятором мы не заканчиваем. Если вы посмотрите в последнюю формулу калькулятора, то обнаружите: разбивка на группы ABC происходит по правилу 80% / 15% /5%. И это зашито жестко в самой формуле.

А что, если пользователи захотят сегментацию 50% / 30% / 20% ? Делать им отдельный модуль под каждую конфигурацию долей? Как бы не так. Когда пользователь будет использовать наш ABC анализ, у него не будет доступа внутрь подмодели (к нашей огромной радости).
Однако прелесть подмоделей в том, что почти любые настройки могут быть вынесены на входной порт переменных, давая пользователям необходимую гибкость. Давайте дадим им возможность самостоятельно определять диапазоны ABC-анализа.
Выйдем из подмодели, зайдем в ее настройки и создадим входной порт переменных. После чего перейдем в настройки порта переменных и создадим 2 переменных:
В метках переменных можно указать, что 1% — 0.01, чтобы не смущать людей. Ну или задавать проценты целыми числами, а внутри калькулятора делить их на 100.
Теперь нам нужно пробросить наши переменные в калькулятор и заменить на них константные значения в финальной формуле. После этого не забываем соединить выход калькулятора с выходом из подмодели.
Все очень красиво, но наш ABC-анализ парит в воздухе, в отрыве от данных, которые остались в первоначальном сценарии. Как нам начать использовать его в других пакетах?
Для этого нам нужно создать производный компонент на основе нашей подмодели. Для этого надо кликнуть по подмодели ПКМ и выбрать соответствующий пункт меню.
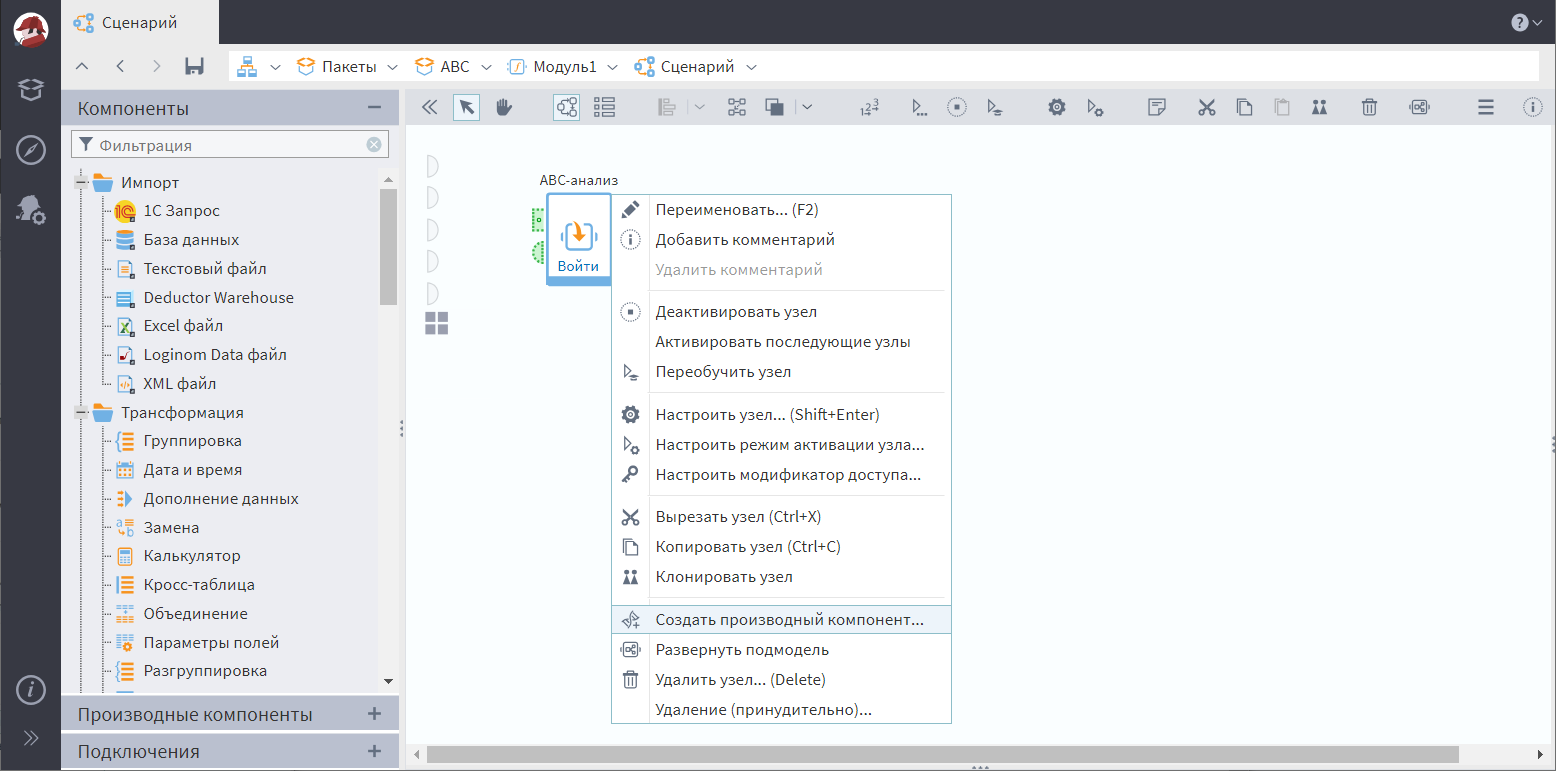
Ставим ему область видимости «Открытый», чтобы он его можно было использовать в других пакетах, жмем кнопку «Добавить».

Теперь мы можем наблюдать его в списке производных компонентов данного пакета.
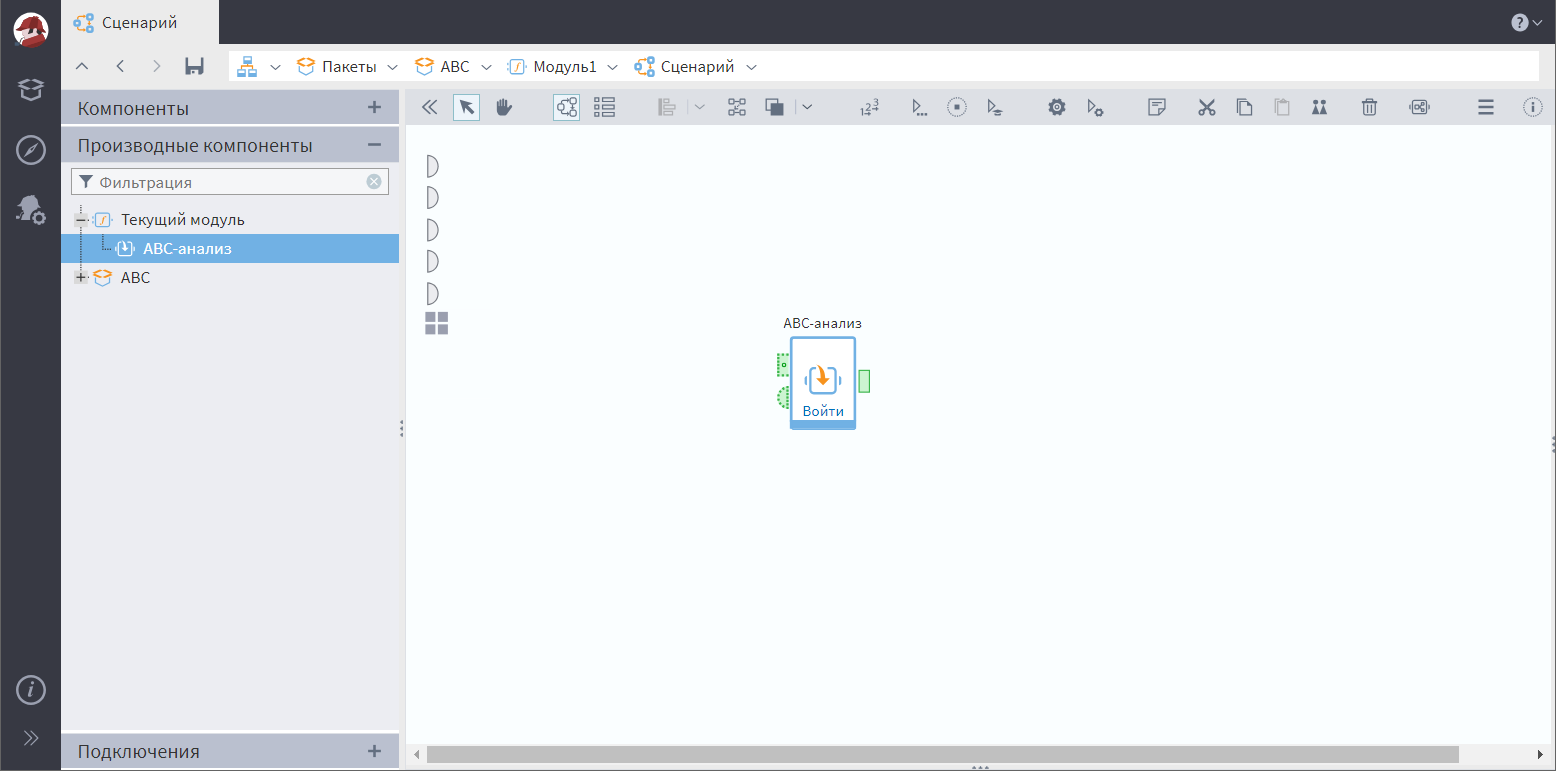
Но как доставить его в первоначальный сценарий с данными?
А теперь давайте проведем ABC-анализ с помощью производного компонента. Подайте на вход данные. Вход загорится красным, т.к. ожидаемые компонентом поля и поля, которые были поданы, не совпадают.
Зайдите в настройки порта, переключитесь в режим отображения Связь и укажите поля:
Таким образом, мы получим анализ типов клиентов по объемам продаж. Настройте границу A как 50%, и B как 30%, используя порт переменных. Оцените итоговый результат, щелкнув дважды ЛКМ по выходному порту производного компонента.
Также на будущее нужно иметь в виду: когда будете создавать библиотеки с большим количеством взаимосвязанных компонентов, вы можете использовать функционал заметок. Он позволит вам разместить цветные подложки под элементами сценария, а также написать произвольный текст внутри них.
Так, вы сможете предоставить пользователю исчерпывающую документацию по вашей библиотеке с минимальными усилиями. Использование эмоджи также поможет упростить восприятие сценария.
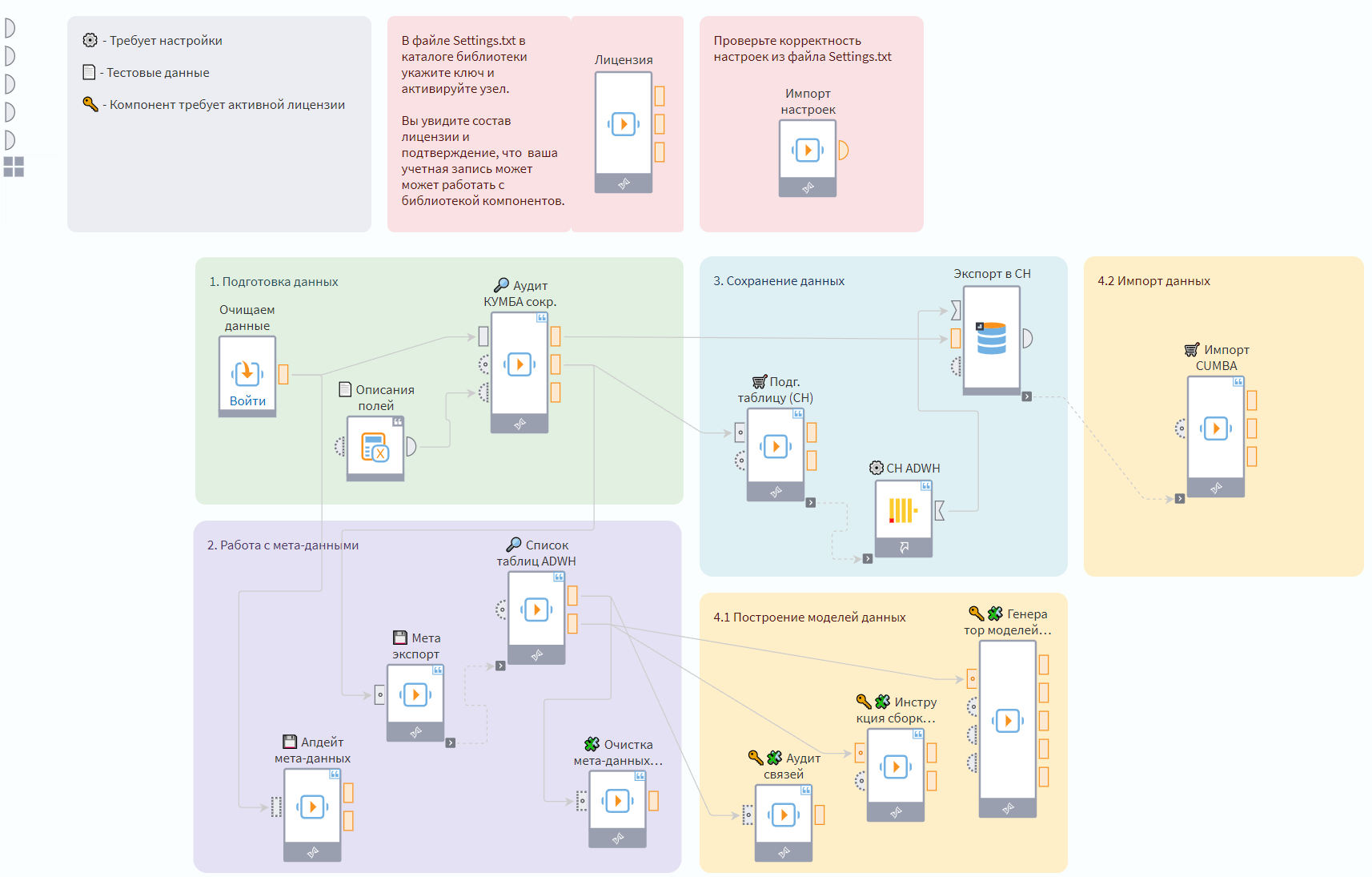
Как вы можете догадаться, с этого момента вас мало волнует, в скольких местах используется ваш компонент. Если вы внесете изменения в исходную подмодель компонента, она будет транслироваться во все пакеты, которые на нее ссылаются.
Оставьте заявку, чтобы получить записи прямых эфиров с экспертами, именной сертификат и доступ к секретному чату
ABC-анализ, конечно, очень простой пример (что не мешает каждому уважающему себя аналитику сделать СВОЙ СОБСТВЕННЫЙ ABC-сегментатор). Однако на нем мы научились:
При таких простых вводных возможности для творчества открываются безграничные.
✔ Хотите масштабировать подходы и стандарты на большую команду, упростив работу бизнес-пользователям? — Вы по адресу.
✔ Хотите сделать мудреную логику на питоне + JS, обернуть ее в производный компонент и отдать бизнес-пользователям? — Пожалуйста.
✔ Хотите оцифровать свою экспертизу и продавать как продукт? — Добро пожаловать.