
В предыдущем занятии мы разобрались с обогащением данных. В нашем распоряжении появилось более 20 дополнительных признаков, позволяющих находить различные виды динамики в клиентской базе. Вопрос в том, кто всем этим будет заниматься.
То, что у пользователя есть возможность найти условное «что угодно» не означает, что он будет этим эффективно пользоваться. Это как пасьянс, где надо переворачивать карты и искать пары. В любой момент можно посмотреть любую пару карт. Но это же надо время тратить, плюс запоминать, что ты уже видел раньше.

Важно! Если вы не ознакомлены с темой предыдущего дня «Перчим, солим и в духовку! Не душно про обогащение данных», то для большего понимания советуем предварительно прочитать этот материал.
Хорошая библиотека компонентов, реализующая сложную бизнес-логику, должна завершаться как минимум одним из способов:
Поэтому финальный компонент нашей Клиентской матрицы — выведение финального рейтинга клиента и присваивание ему одного из семнадцати клиентских сценариев.
Конечный узел добавляет набор полей с префиксом ИР (итоговый рейтинг). Что это за поля?
Указанные файлы находятся в одной папке с клиентской матрицей.
Вам не нужно ничего в них менять. Однако обратите внимание на сам факт размещения этих настроек во внешних файлах. Эта практика очень полезна, когда ваша библиотека требует определенных разовых настроек. Не стоит захламлять ими порты и давать возможность пользователю что-то в них поправить.
Также это полезно для сложно структурированных настроек. В нашем случае большая часть параметров задается в матричном виде. При этом во время загрузки в Loginom таблицы транспонируются для удобного слияния с массивом основных данных с помощью узла Свертка столбцов.
Повторяем действия с 2 весовыми коэффициентами — переходим к расчету итогового сценария.
Что дальше делать с интерпретированными сценариями?
На этом марафоне вы познакомились с правилами разработки производных компонентов, а также с выстраиванием архитектуры компонентов для сложной бизнес-логики, а именно:

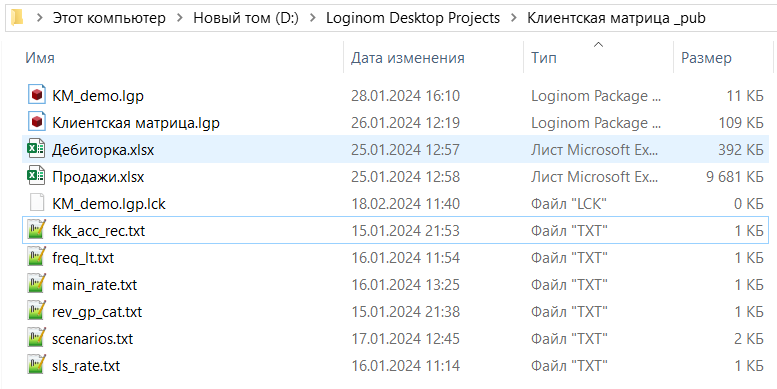
Когда данные обогащены и классифицированы, самый простой способ — добавить в них ясность по дальнейшим действиям и попарно группировать их в «сводные рейтинги» до тех пор, пока не придете к единому признаку.
Проще всего это делать с помощью матриц, которые на пересечении 2-х признаков останавливают некое итоговое значение. Можете посмотреть пример в файле rev_gp_cat.txt в папке с клиентской матрицей.
Там перекрещиваются уровни выручки (по вертикали) и уровни валовой прибыли (по горизонтали).

Примечания разработчика: т.к. мы не знаем заранее, какие диапазоны будут установлены пользователем, мы полагаемся на нумерацию классов. Внутри финального узла мы преобразуем классы выручки в соответствующие кодовые обозначения.
А значения из текстового файла разворачиваем в строковый вид, чтобы можно было выполнить слияние.
При работе с клиентской матрицей мы придерживаемся следующей терминологии оценок:
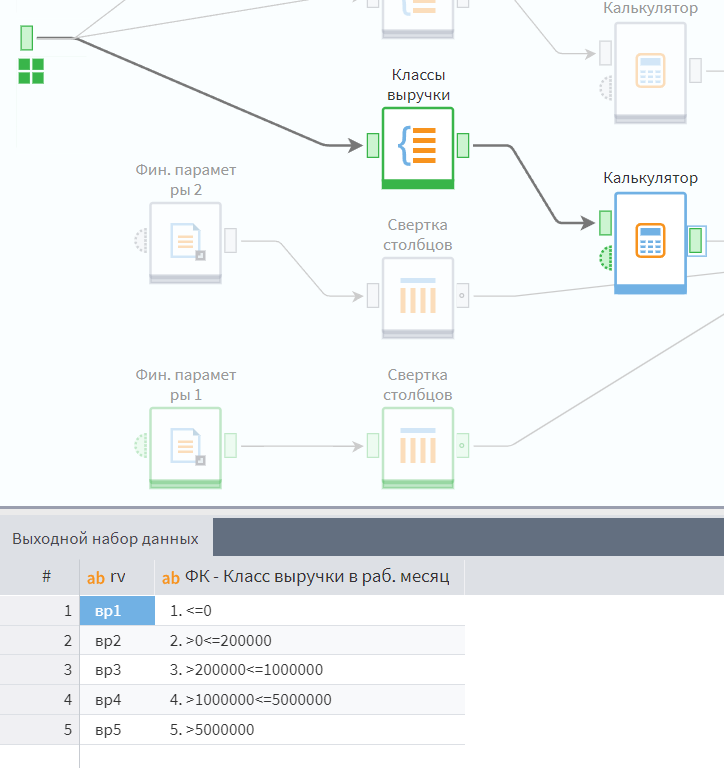
После применения первого набор параметров, применяем последующие наборы для корректировки. Например, после классификации «Выручка/валовая прибыль», мы полученный рейтинг корректируем на уровень дебиторской задолженности, с помощью файла fkk_acc_rec.txt.
По горизонтали идет уровень дебиторской задолженности, по вертикали — финансовый рейтинг из предыдущего шага.

Как видите, финансовый рейтинг клиента может быть улучшен или ухудшен в зависимости от его платежной дисциплины. Итого: мы применяем следующую схему сведения финального рейтинга.

Схема сведения финального рейтинга
Сведение в итоговый вес происходит как определение среднего арифметического между частотным классом и финансовым классом 3, по принципу: vip=4, a=3, b=2, c=1, d=0.
Таким образом, любую комбинацию параметров можно свести к единому значению через последовательность шагов. Главное — последовательности должны начинаться с самых важных факторов и как бы уточняться на следующих шагах.
