
Представьте, что вы идете по улице и находите купюру 5 000 рублей. Вокруг — никого. Вы беспрепятственно забираете деньги себе. Надо ли отныне планировать жизнь с расчетом на то, что каждый день на дороге будут лежать 5 000 рублей? Вовсе нет, потому что это редкое событие :(
При принятии решений на основе данных нужно учитывать, что в анализируемом потоке могут попадаться уникальные события, например, продажи редких товаров. Но почему это должно кого-то беспокоить? Ведь имеется хоть и редкое, но реальное событие.
На самом деле все не так просто, т.к. наличие в ассортименте редко покупаемых товарных позиций приводит к проблемам.
Во-первых, бизнес может нести непропорционально большие затраты на инфраструктуру для хранения подобной продукции. Место на складе занято товарами, которые покупают раз в год, а его можно было бы использовать для продукции с высокой оборачиваемостью.
Во-вторых, процесс работы с такими товарами может быть сложнее, чем с ходовыми SKU. Т.к. их количество невелико, нужно отслеживать наличие, отдельно заказывать, формировать партии. Проблема не только в сложности бизнес-процесса, но и в том, что это отнимает ресурсы от работы с популярными позициями.
В-третьих, прогнозы и статистические расчеты на данных, в которых встречаются редкие значения, как правило, получаются менее точными.
По тексту выше можно подумать, что редкие значения — разновидность фейковых данных, но это не так.
Фейковые данные искажают картину из-за того, что эта информация недостоверная (например, несуществующие клиенты) или не имеющая отношения к изучаемому процессу (например, покупки частными лицами при изучении оптовых продаж).
С редкими событиями все не так. Они отражают достоверную информацию и относятся к изучаемому процессу, но низкая частота событий не позволяет их использовать для формирования надежных выводов. Это связано с тем, что каждое редкое событие — уникальное, а следовательно трудно прогнозируемое.
Для работы с ними нужно придумать способ превращения уникального события в обычное, например, за счет объединения нескольких редких событий в одно не столь уникальное.
История аптечной сети. Ассортимент даже маленькой аптеки — тысячи позиций. Значительная его часть – достаточно ходовые наименования. Однако встречаются и редкие медикаменты. Можно их исключить из ассортимента, но при таком уровне конкуренции, как в этом бизнесе, когда в любом доме по 2-3 аптеки, важен каждый клиент, а значит и покупатель редких лекарств.
Решение было найдено: компания открыла «Аптеку редких лекарств», в которую в основном завозились редкие позиции. В результате туда приходили покупатели не только с окрестных домов, но и со всей округи. Таким образом, был консолидирован спрос на редкое со всего города.
Ведь если редкое случается часто, оно перестает быть редким! Кроме того, аптека смогла улучшить условия закупок, потому что теперь работала с более крупными партиями.
Устойчивый бизнес базируется на регулярных процессах. В идеале хочется продавать ходовые товары стабильно покупающим клиентам, а любое редкое событие нарушает ритмичность процесса и повышает издержки.
Важно! Если вы не сделали практику в теме «Fake-патруль. Разоблачаем фиктивные данные», то предварительно требуется открыть решение задания предыдущего дня, скачав его ниже.
rarРешение практического задания. День 8.lgp
В начале необходимо понять, сколько клиентов приобретает редкие позиции, и как это влияет на продажи. Нужно выделить редкие товары и посчитать, какой процент от закупаемого ассортимента у каждого клиента они составляют.
Самый быстрый способ проверить наличие редких значений — посмотреть детализацию Гистограммы в визуализаторе Качество данных.
Начать стоит с поля Группа товаров. Если редко продаются все SKU из целой группы, то это тревожный сигнал.
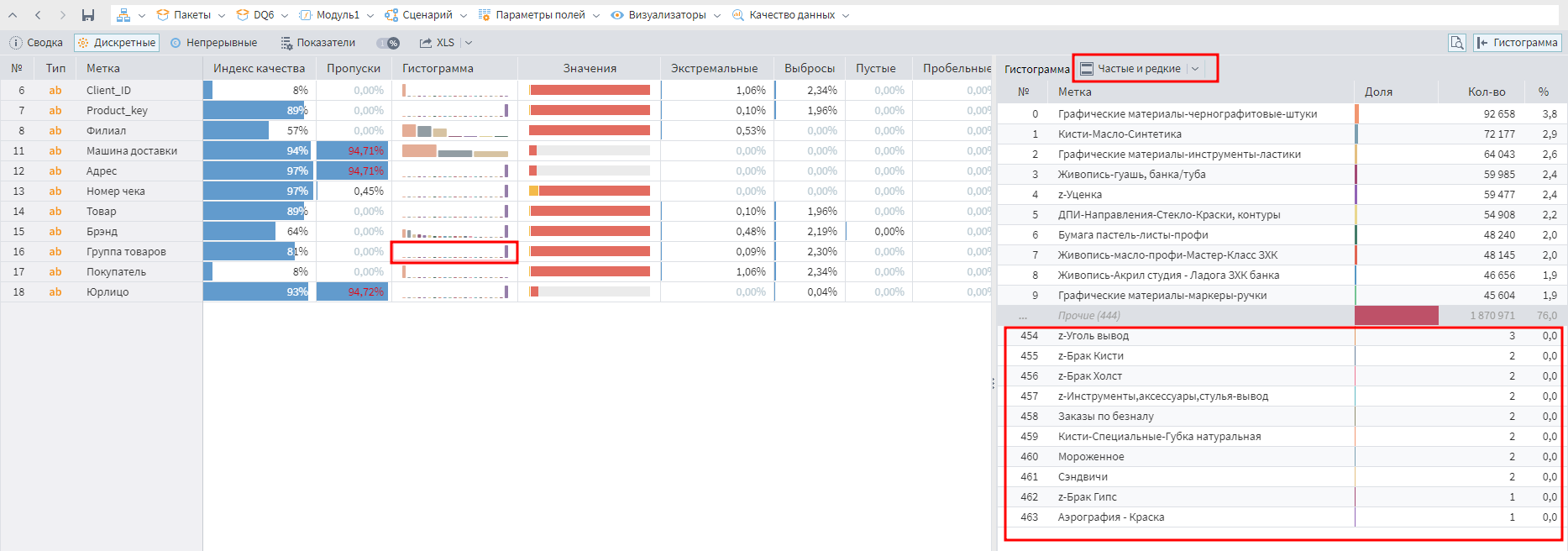
Как видно по гистограмме, редко продаваемые группы встречаются. Товары из некоторых групп были приобретены всего пару раз за несколько лет! Теперь можно оценить, какие клиенты часто покупали редкие позиции.
Для этого понадобится сформировать список групп товаров. Его можно получить с помощью узла Группировка. Заведем в него выход из подмодели Продажи.
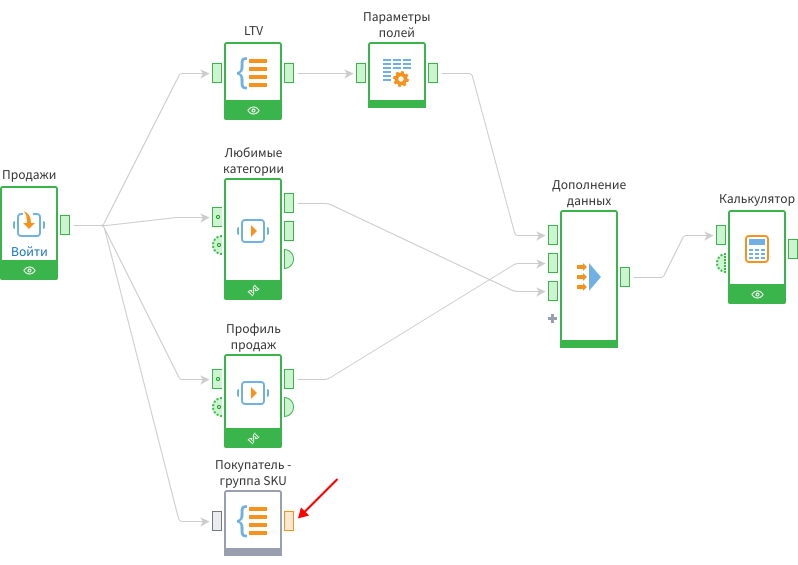
В настройках укажем группы Client_ID и Группа товаров.

Помимо этого нужно рассчитать, сколько раз каждая категория товаров продавалась всем клиентам.
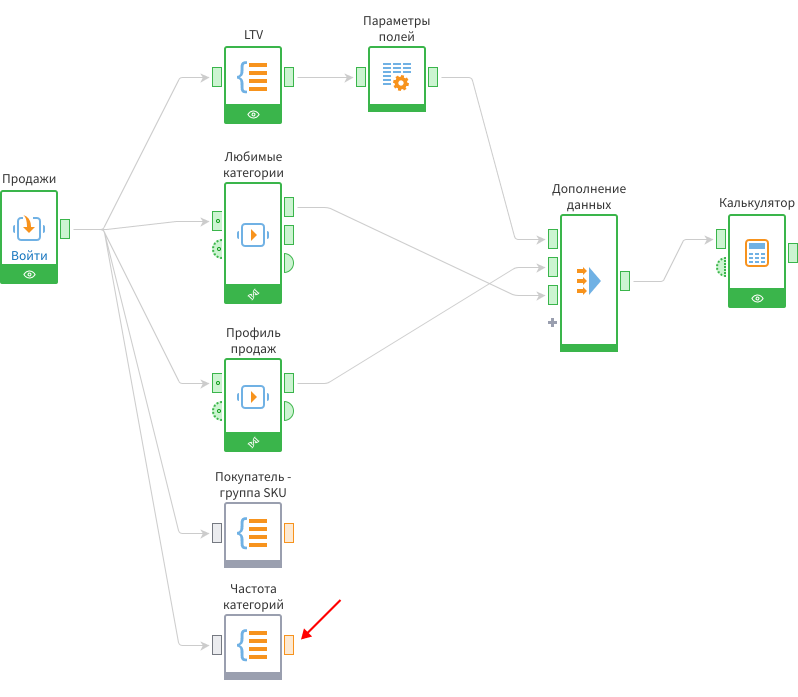
Для подсчета нужно использовать еще одну группировку, в которой будет подсчитано количество уникальных номеров чеков в разрезе товарных групп.

Информацию из этих узлов необходимо соединить при помощи компонента Слияние по полю Товарная группа. Получится таблица, где напротив каждой приобретенной клиентом категории будет общее число продаж этой группы за все время.
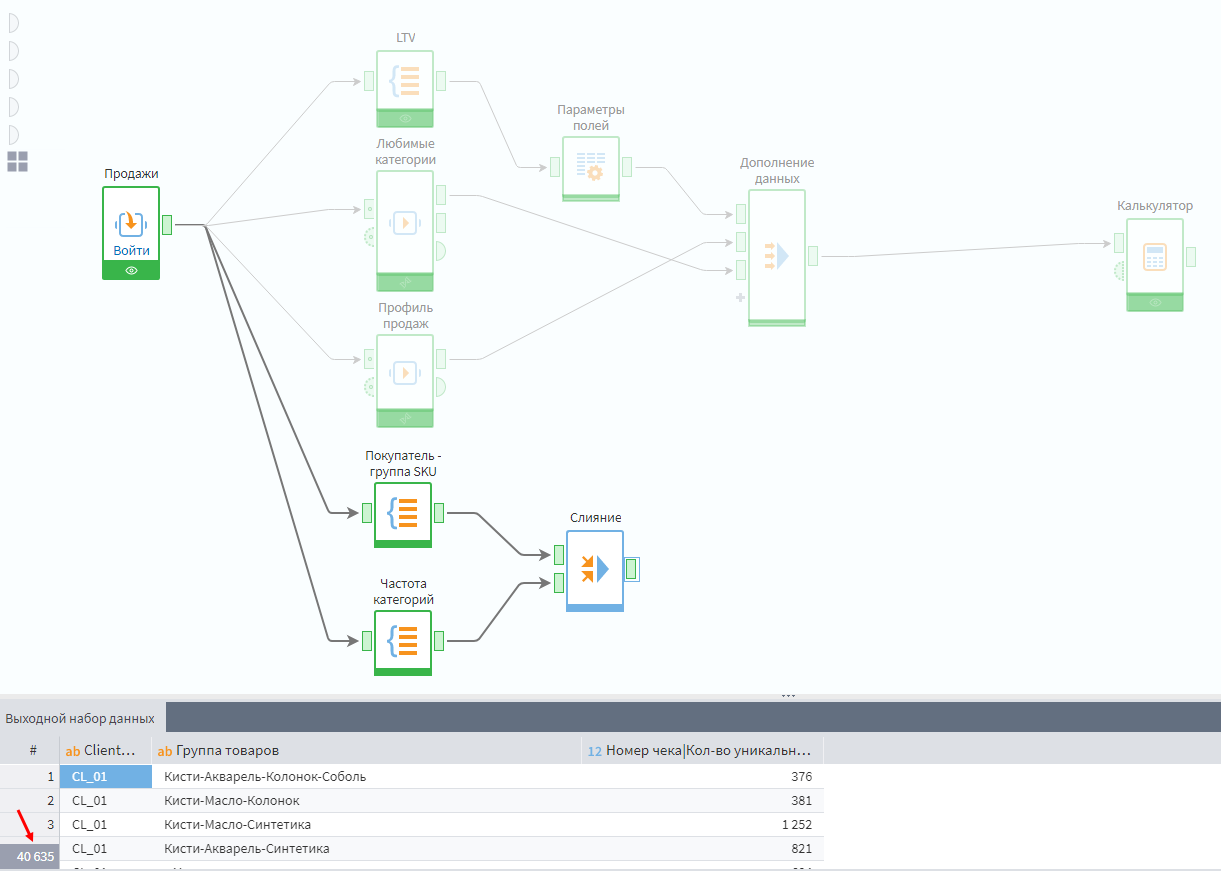
Для расчета процентного соотношения редких и нередких товаров в ассортименте клиента нужно использовать Калькулятор.
Надо создать числовое поле Rare, которое будет содержать 1, если количество общих продаж категории меньше 50, и 0, если больше.

Далее с помощью Группировки можно подсчитать количество категорий, которые купил клиент, и сколько из них — редкие.
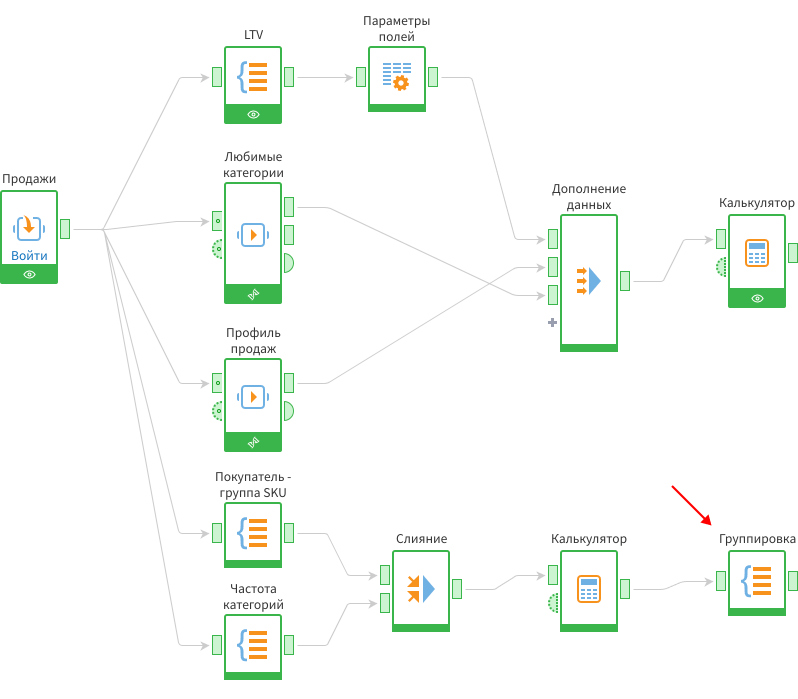
Настройки Группировки выглядят так: в разрезе ID клиента мы считаем сумму по полю Редкая категория (там 1 или 0) и общее количество купленных товарных групп.

Осталось преобразовать вычисления в аналитический признак. Для этого надо добавить еще один Калькулятор после Группировки, а в нем посчитаем 2 поля: % редких — как количество редких деленное на общее количество, и Класс редкости — текстовое описание.

Текстовое описание редкости формируется следующим образом:
if(RarePerc<=0.1,"1. Стандартный", if(RarePerc<=0.5,"2. Энтузиаст","3. Любитель экзотики"))

Следующим шагом стоит избавиться от вспомогательных полей, которые далее не требуются. Для этого можно добавить после Калькулятора узел Параметры полей и исключить поля Rare и SKU_group_name.

Получившуюся таблицу надо связать с узлом Дополнение данных. Таким образом в результирующей таблице появится еще один аналитический атрибут.
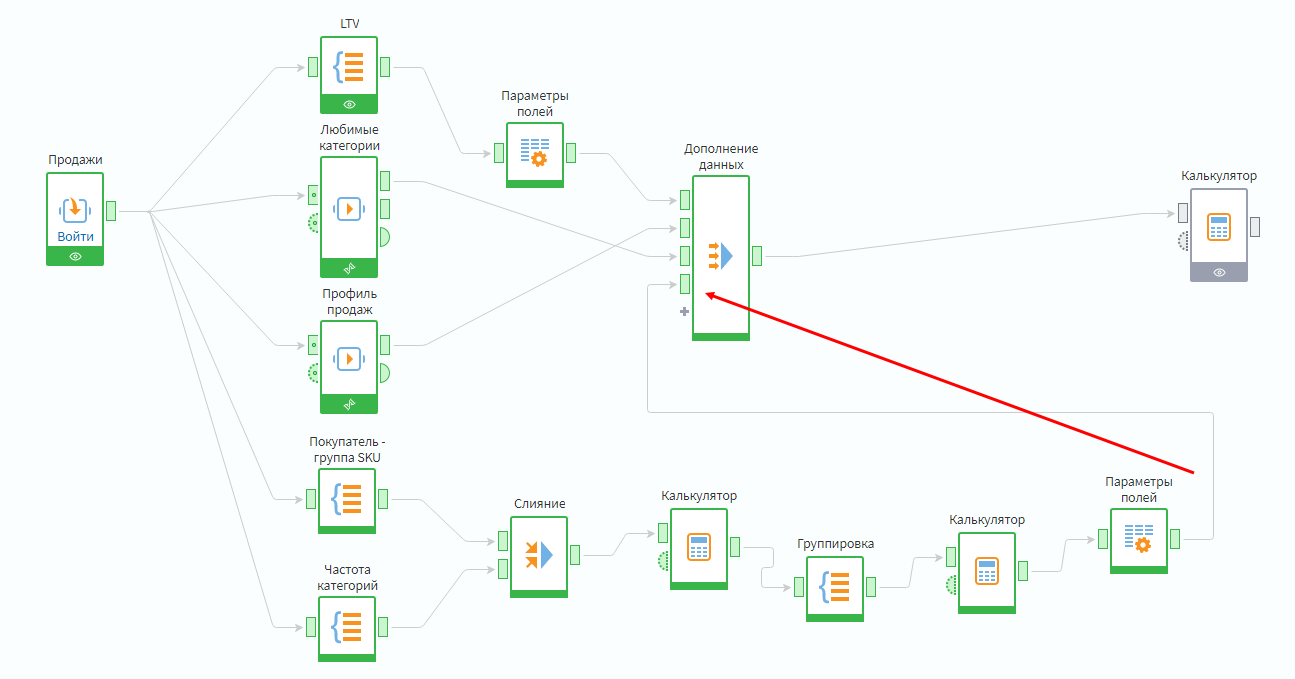
При настройке присоединяемой таблицы нужно указать, что связывание происходит по полю Client_ID.

Полученную цепочку действий рекомендуется свернуть в подмодель, чтобы схема была более читаемой.
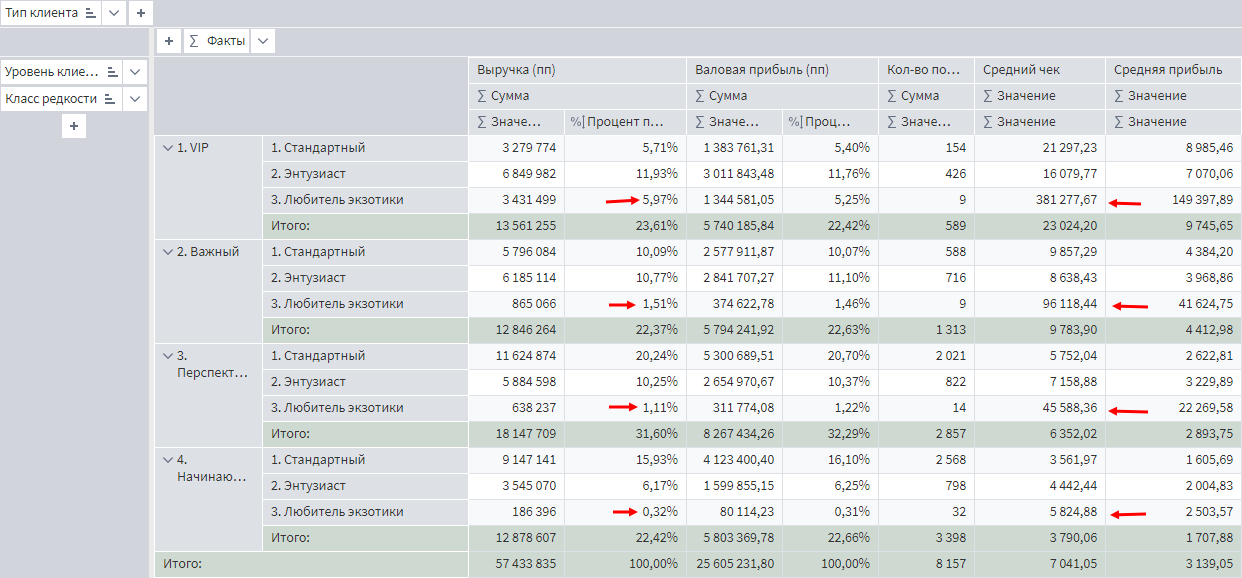
При добавлении нового атрибута Класс редкости в отчет Портрет клиента выявляются интересные детали.
У клиентов всех сегментов имеются покупки позиций разных уровней редкости. Для редких товаров характерен самый высокий средний чек, но более или менее существенную долю прибыли в 5.25% любители экзотики дают только для VIP-класса. Во всех остальных случаях эта доля не превышает 2%.
Учитывая, что количество VIP-клиентов невелико, стоит оценить, какую реальную нагрузку они оказывают на отдел закупок, и как это соотносится с общей эффективностью.
Теперь есть возможность оценить характеристики только тех клиентов, которые закупают самый ходовой ассортимент, и понять, чем они отличаются от любителей экзотики.
Задание для техно-энтузиастов. Создайте на подмодели Редкие товары входной порт переменных. Создайте в нем переменную типа целое число, назвав ее Порог редкости.
Передайте переменную на вход калькулятора, в котором проставляется признак 1 или 0 в зависимости от редкости категории. Измените формулу так, чтобы вместо константного значения 50 шло сравнение с переменной.
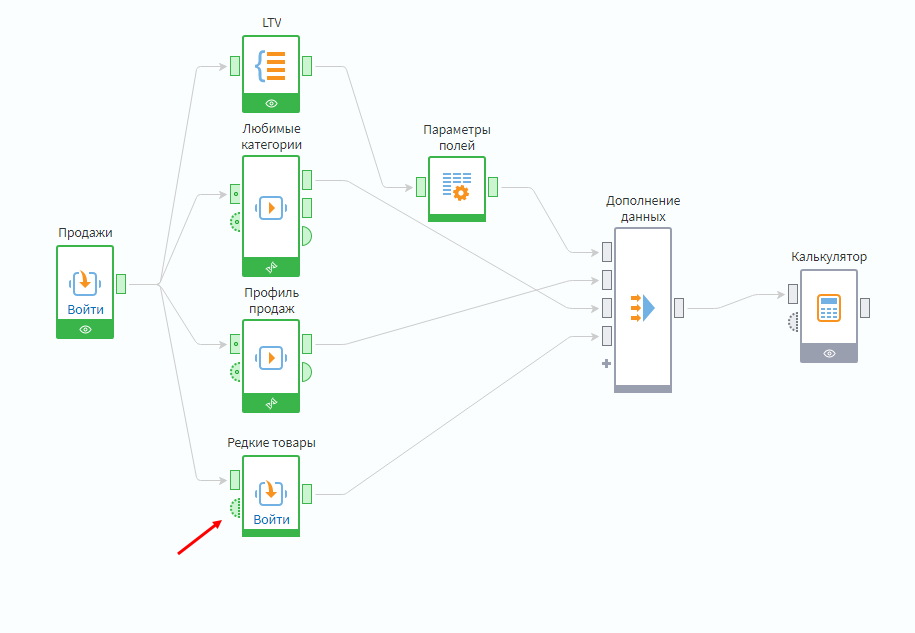
Теперь можно настраивать уровень определения редкости, не заходя в подмодель.

Эксперт марафона: Евгений Стучалкин, руководитель и архитектор self-service решений BI2BUSINESS