
В предыдущие дни проблемы в данных обычно заключались в том, что их больше, чем нужно: дубли или фейковые данные избыточны для анализа.
Важно! Если вы не сделали практику в теме «Data раскопки. Анализируем редкие значения», то предварительно требуется открыть решение задания предыдущего дня, скачав его ниже.
lgpРешение практического задания. День 9.lgp
Сегодня будет рассмотрена обратная проблема — пропуски, т.е. отсутствие данных. Их можно разделить на 2 вида:
Первый тип проблем легко обнаружить с помощью визуализатора Качество данных. Если просмотреть данные по клиентским транзакциям, то наличие пропусков сразу бросится в глаза.
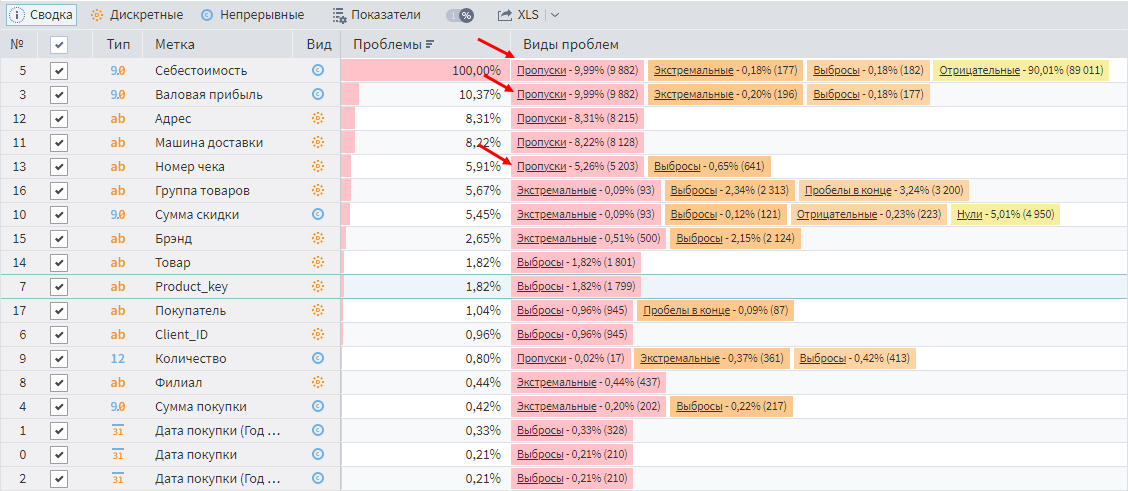
Пропуски в данных
Реакция на проблему зависит от целей анализа. Иногда пропуски можно игнорировать. Например, на отсутствие значений в полях адреса и машин доставки можно не обращать внимание, если не интересуют вопросы транспортировки.
А вот пропуски в себестоимости игнорировать нельзя. Особенно если учесть, что анализируется Валовая прибыль, являющаяся суммой между между Суммой продаж и Себестоимостью. Себестоимость задается отрицательной.
Если в арифметических расчетах имеется null-значение, то результат тоже будет пустым. Как следствие для некоторых записей валовая прибыль отсутствует, и данный показатель по всей базе получится заниженным.
Также стоит обратить внимание на пропуски в поле Номер чека. Оно используется для расчета количества транзакций, что, в свою очередь, учитывается при вычислении среднего чека. Таким образом, получается заниженное количество транзакций и завышенное значение среднего чека.
Причин обычно две: технические проблемы или брак бизнес-процесса.
К возникновению пропусков в номере чека привела типичная техническая проблема. В компании используется контрольно-кассовое оборудование разных производителей. Данные с них попадают в единую базу. Часть оборудования формировала номер чека как число, а часть – как микс числа и текстовых символов.
При этом в консолидированной базе под хранение номера чека отведено числовое поле. В результате часть значений, которые удалось конвертировать в число, попали в базу, а часть — стала пустым (null) значением.
Еще одной частой причиной пропусков является человеческий фактор, усугубленный сложным бизнес-процессом.
Например, сотрудник, принимающий товар от поставщиков, должен прописывать его закупочную стоимость в учетной системе, но регулярно этого не делает. Причины могут быть разные: не успевает или забывает, лень, нет корректных данных на момент ввода, анализ себестоимости вне его зоны ответственности...
Поэтому контроль качества вводимых данных лучше всего автоматизировать. В частности, с забывчивостью можно бороться настройкой обязательных полей в учетных системах. Правда, это не спасает от фейковых данных, когда в обязательное поле Телефон вписывают +123456789.
Человеческий фактор нельзя игнорировать. Его влияние слишком велико. Значит, все, что может собираться и проверяться автоматически, должно быть автоматизировано:
Далеко не всегда есть возможность исправить проблемы задним числом, например, заполнить пропущенные значения, поэтому борьбу за качество данных рекомендуется начинать на этапе их ввода.
Вначале продумаем, как заполнить пропуски в номерах чеков. В идеале хотелось бы восстановить реальную информацию из систем учета, но это не всегда возможно. Поэтому попробуем заполнить эти пропуски при помощи сценариев в Loginom.
Так как анализируются продажи оптовым клиентам, то можно отталкиваться от предположения, что каждому контрагенту в день осуществляется не более одной отгрузки. Если отгрузок несколько, то на практике довольно часто их объединяют в одну.
Следовательно, пустой идентификатор чека можно заменить на комбинацию полей Client_ID и Даты продажи. Это можно сделать, используя компонент Калькулятор в подмодели Продажи.
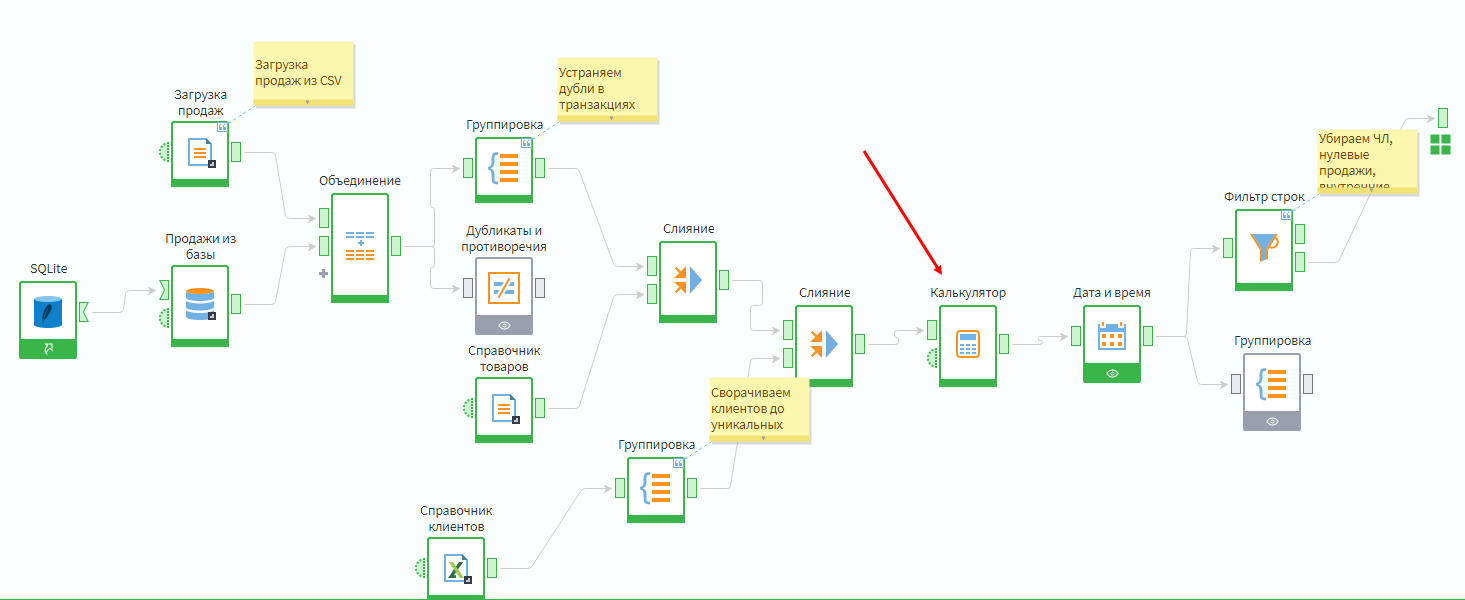
Необходимо добавить текстовое поле New_CheckID. В качестве формулы задать объединение двух полей через разделитель _.
Составные поля рекомендуется соединять через разделитель. Это не только повышает читаемость значения, но и позволяет избежать коллизий, например, когда соединение 11 и 1, дает такой же результат, как соединение 1 и 11.

Данное действие сформировало новое поле, а не заменило старое. Не хотелось бы теперь искать места по всему сценарию, где нужно внести исправления, чтобы все работало как надо.
Чтобы подменить значение одного поля другим, требуется настроить соответствующую связь на выходе из узла. Порядок действий следующий:
Подробнее в видео:
После этих действий на выходном порту узла появится точка. Это значит, что в узле отключена автосинхронизация, и теперь перечень полей, выходящих из Калькулятора, управляется вручную. Так, если во входной таблице появится новое поле, то чтобы оно появилось на выходе, нужно будет его туда самостоятельно добавить.
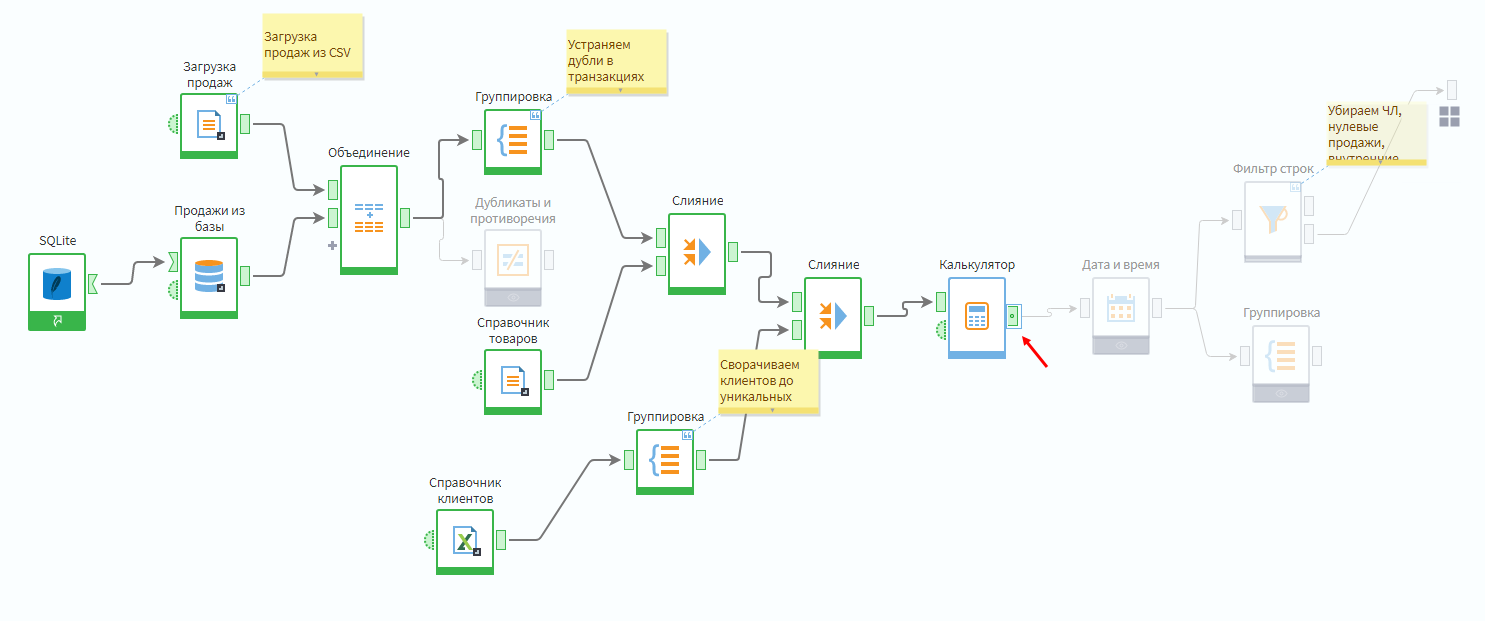
Отключенная автосинхронизация
Следующий вопрос — заполнение пропусков по полю Себестоимость.
Самое простое решение, приходящее в голову, — отфильтровать все записи с пустым значением данного поля. Проблема в том, что тогда исключится слишком много строк, что повлияет на другие показатели.
Если при анализе реальных данных отбрасывать все строки с пустыми значениями в любом поле, то скорее всего анализировать будет нечего. Пропуски в данных встречаются слишком часто.
Следовательно, надо каким-то образом «восстановить» цену закупки. Конечно, для этого придется принять некоторые разумные допущения. Они не смогут гарантировать 100% корректность, но позволят получить адекватный портрет клиента, чего в данном случае достаточно.
Если оставить как есть, то в отчетах будут заниженные данные по валовой прибыли и неверное понимание ценности клиентов. Так как пропуски есть примерно в 10% транзакций, то расчет себестоимости, основанный на разумных допущениях, – меньшее зло по сравнению с отсутствием у десятой части продаж данных по прибыли.
Подобные действия надо документировать, чтобы пользователи отчетов осознавали, что имеют дело с не совсем точной информацией.
«Восстановить» себестоимость можно с помощью статистики. Например, отталкиваться от средней наценки на все позиции или конкретную товарную группу. Можно построить и более сложные модели, но для экономии времени предлагается реализовать следующий сценарий: рассчитать медианный процент прибыли для всех товаров и использовать его, когда реальная себестоимость не известна.
Надо в подмодели Продажи добавить фильтр по условию Поле себестоимость — не пустое.
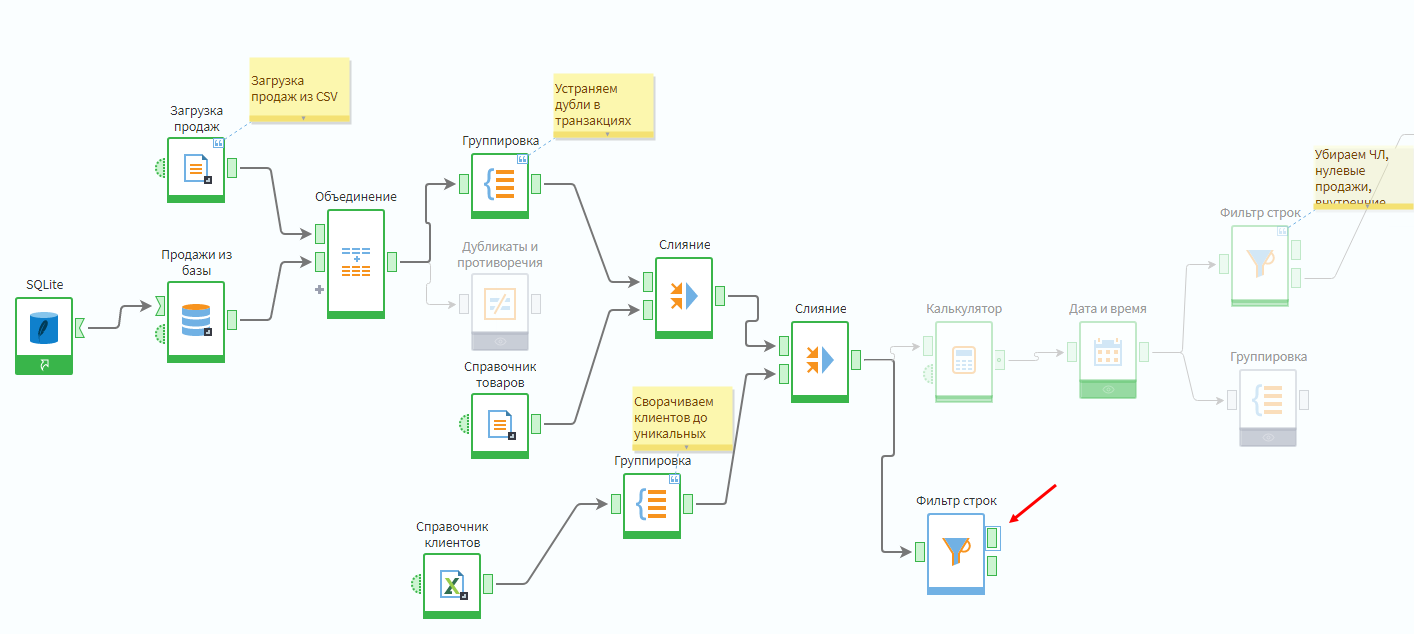
Далее сгруппировать данные строк, где себестоимость не пустая, по товарным группам, просуммировав поля Себестоимость и Сумма покупки.
Группировка по товарным категориям

Следующий шаг — добавить еще один калькулятор, в котором будет рассчитано поле Profit_perc по формуле (Summa_pokupki+Sebestoimost)/Summa_pokupki.
Получится таблица с процентом прибыли по каждой категории товаров.
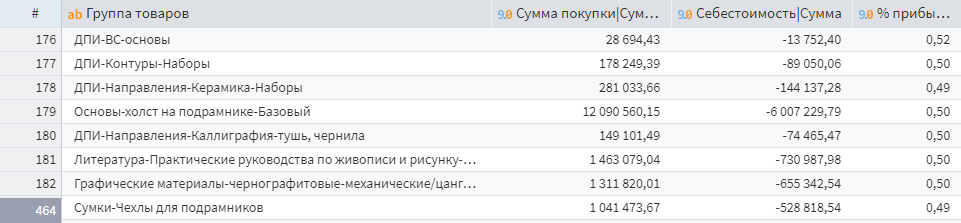
Процент наценки по группам товаров
Пометка. Значение последнего столбца % прибыли по факту является долей.
Далее нужно рассчитать медианный процент наценки по группам. Для этого можно использовать обработчик Таблица в переменные, передав полученный результат на вход Калькулятора.
Расчет медианной наценки по группам товаров
Логика этого узла похожа на обработчик Группировка, но без возможностей указания групп. Из каждого поля рассчитывается одно или несколько агрегированных значений, которые передаются дальше по сценарию как переменные. Нужно указать агрегацию медиана для поля % прибыли.

Теперь медианный процент прибыли доступен как переменная в Калькуляторе.
Расчитанная наценка в калькуляторе
Далее нужно модифицировать формулу для поля Gross_profit так, чтобы в случае пустого поля Sebestoimost прибыль считалась как выручка, умноженная на медианный процент прибыли. В ином случае – как сумма выручки и себестоимости (заданной отрицательным числом).

Для того, чтобы сценарий стал более компактным, нужно свернуть узлы, в которых рассчитывалась медианная наценка в подмодель. Для этого надо выделить их по очереди, прокликав ЛКМ с зажатым Ctrl, а затем выбрать на панели инструментов действие Свернуть в подмодель.
Бонусное задание. Создайте дополнительное поле расчета себестоимости, в котором при пустом значении поля Sebestoimost будет происходить вычисление себестоимости через вычитание из валовой прибыли суммы продажи (в исходных данных себестоимость идет со знаком минус по стандартам финансовой отчетности).
Последний шаг — настройка выхода из узла, чтобы новое поле себестоимости передавалось в старое по аналогии с номером чека.
Пропуски в значениях полей — не единственный вид отсутствующих данных. Иногда могут выпадать целые блоки, например, продажи за неделю или месяц. Как понять, есть ли подобные проблемы в данных?
К сожалению, ошибка может проявлять себя только в виде расхождений в отчетах. Ведь речь идет не о пропусках в ячейках, а об отсутствие самих строк. Нет строк — не видно проблем.
Поэтому при наличии сложных ETL-процессов необходима реализация механизмов мониторинга корректности загрузок: анализ логов, контроль завершения задач, сравнение данных в первоисточнике и хранилище данных и прочее.
Одна из самых распространенных проблем такого рода — не прогруженные записи. Чаще всего продажи осуществляются каждый рабочий день, и отсутствие хотя бы одной отгрузки в какой-то день — надежный индикатор проблем, возникших в ETL-процессе. В Loginom нет готового обработчика для выявления таких проблем, но его можно реализовать средствами платформы.
До этого момента подмодели использовались для оптимизации рабочего пространства за счет сворачивания больших фрагментов сценария. Но сейчас будет спроектирована подмодель, которая может переиспользоваться как готовый компонент в других сценариях.
Подмодель будет принимать на вход поле с датой, а на выход возвращать список пропущенных периодов. При этом особо длительные пропущенные периоды будут выводиться отдельно.
Добавьте компонент Подмодель в область сценария, где создается клиентский портрет, и зайдите в настройки узла.
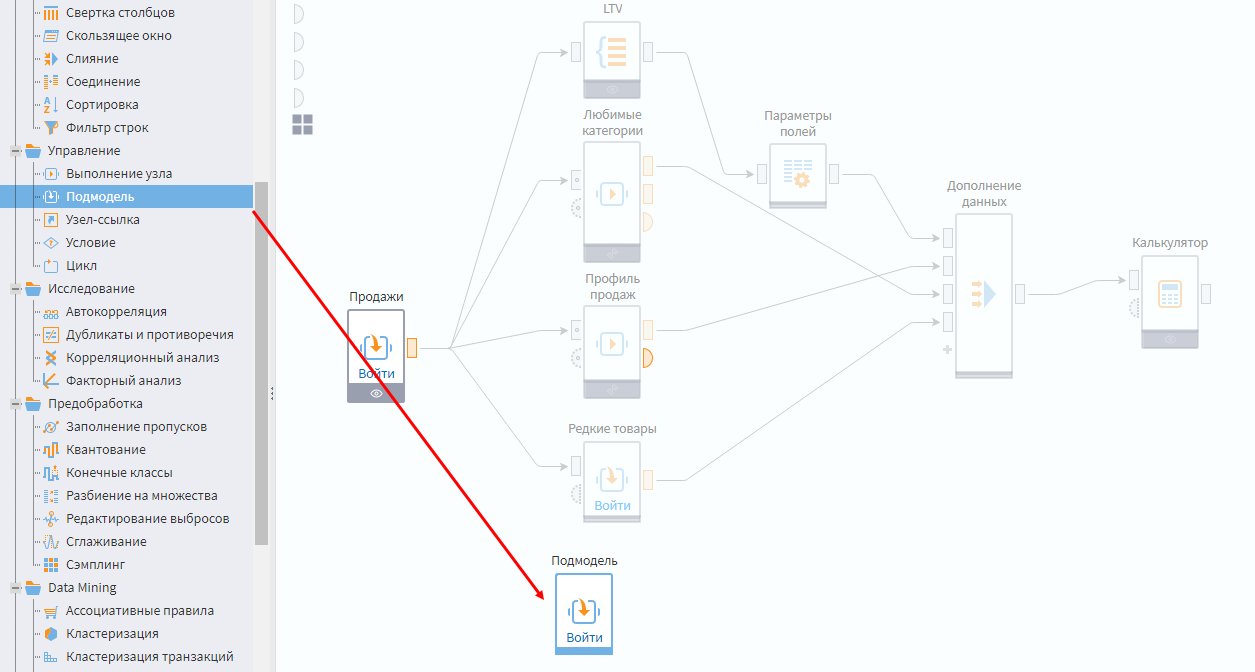
Создание подмодели
Нужно создать на входе 1 табличный порт и 1 порт переменных, а на выходе — 2 табличных порта.

При создании портов, особенно если их несколько, надо давать им понятные названия. Иначе в будущем такую подмодель будет сложно поддерживать самому и переиспользовать коллегам. Название порта помогает разобраться, какие данные туда подаются.
Результат:

Т.к. подмодель рассчитана на решение конкретной задачи (работа с данными определенного типа), стоит задать перечень полей и переменных на входных портах.
В табличном порту нужно отключить автосинхронизацию и создать поле Date с типом Дата.
В порту переменных надо отключить автосинхронизацию и создать переменную с типом целое число и значением по умолчанию — 10.
На вход подмодели надо подать данные из узла Продажи, а в настройках входного порта данных задать соответствие между полем Дата покупки и Date, переключив отображение в режим Связи.

В подмодели определены входы, теперь надо построить сценарий от входа до выхода. Для этого нужно сформировать набор уникальных дат и отсортировать их по возрастанию.
Т.к. заранее неизвестно, содержатся в поле только даты или это поле с датой и временем, надо с помощью функции int() округлить значения. В полях этого типа целая часть числа отвечает за дату, а дробная — за время.


Дальше при помощи Группировки нужно сформировать перечень уникальных дат и отсортировать по возрастанию.


Потом рассчитать, есть ли пропуски. Для этого на вход последнего узла подать ранее отсортированную таблицу.

Следующий шаг — рассчитать, сколько дней между соседними строками. Для этого используется функция Data().
Первым аргументом (в двойных кавычках) идет название поля, из которого берутся данные. Вторым аргументом — номер строки. Функция RowNum() возвращает номер текущей строки, следовательно, вычитание единицы дает номер предыдущей строки.
Дополнительно нужно вычесть единицу, т.к. между текущим и следующим днем всегда разница в 1 день, а требуется найти дни между которыми разница больше, чем один пропущенный день.

Далее надо добавить пару полей, которые будут показывать нам пропущенные периоды.


При помощи обработчика Параметры полей можно убрать поле DateR, т.к. на выходе интересуют только пропущенные интервалы.

После исключения поля DateR нужно добавить узел Фильтрации с условием Пропущено дней > 0.

Фильтрация записей
Далее надо добавить еще один Фильтр, принимающий данные с узла Параметры полей и показать в данном узле порт переменных, который по умолчанию скрыт. Для этого надо кликнуть по последнему узлу фильтрации ПКМ и в меню выбрать пункт Отобразить порт управляющих переменных.
Некоторые узлы имеют скрытый порт переменных, который при необходимости можно отобразить описанным выше образом.
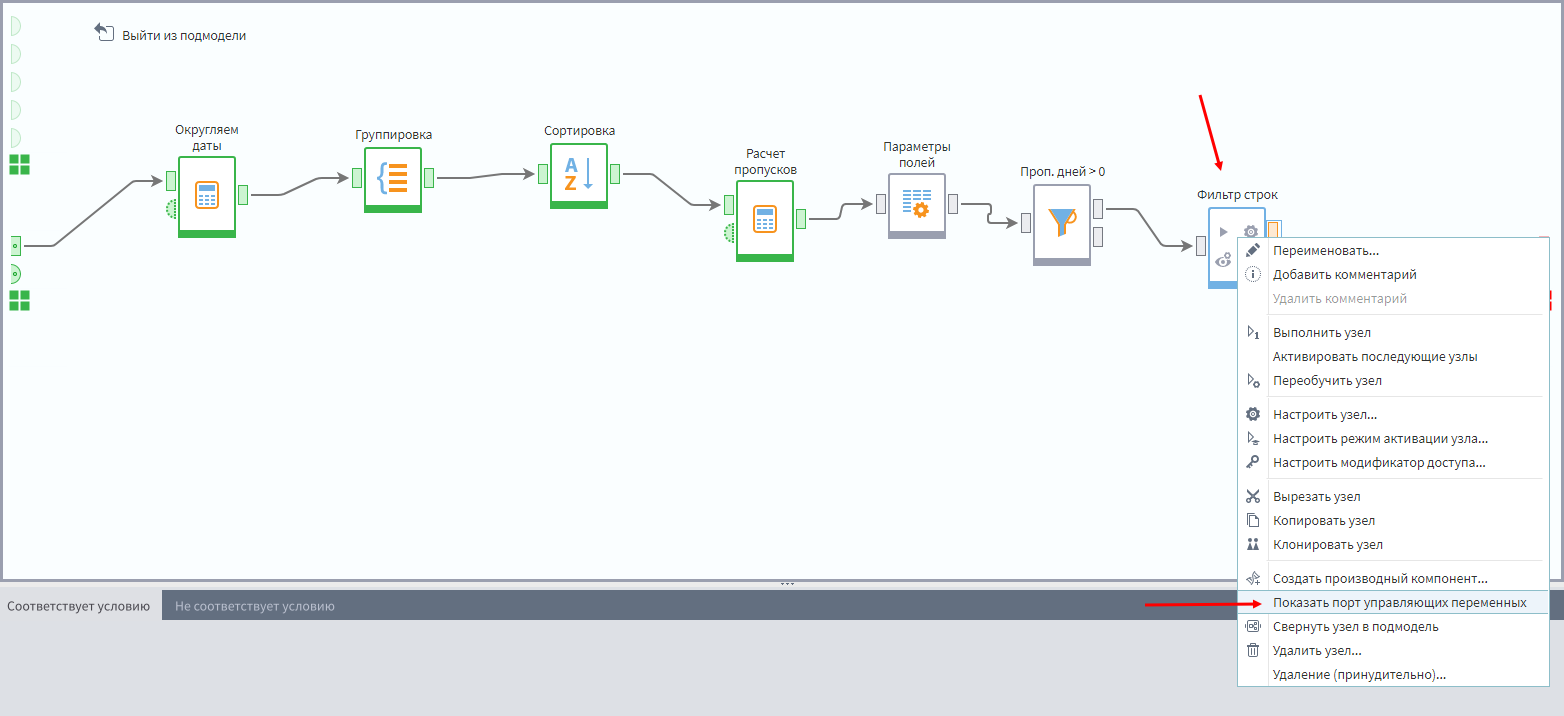
На этот порт переменных нужно подать данные с порта переменных подмодели.
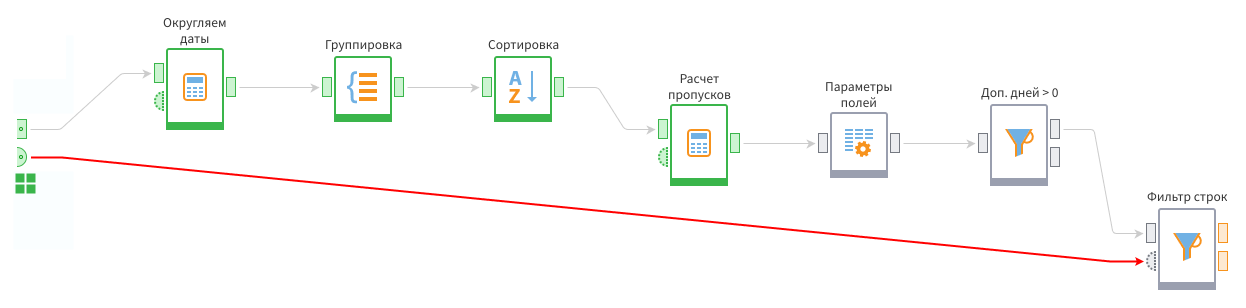
Теперь при открытии мастера настройки фильтра надо активировать соответствующий переключатель напротив параметра и выбрать нужную переменную.

После постановки условия фильтрации, будут отбираться записи, в которых длина пропуска больше или равна значению из переменной.
Финальный этап — отправить выход с первого фильтра на первый входной порт подмодели, а со второго фильтра — на второй выходной порт. Теперь в них будет выводиться полный список пропусков и отдельно большие пропуски. Критерий большого пропуска определяется через переменную на входе в подмодель.
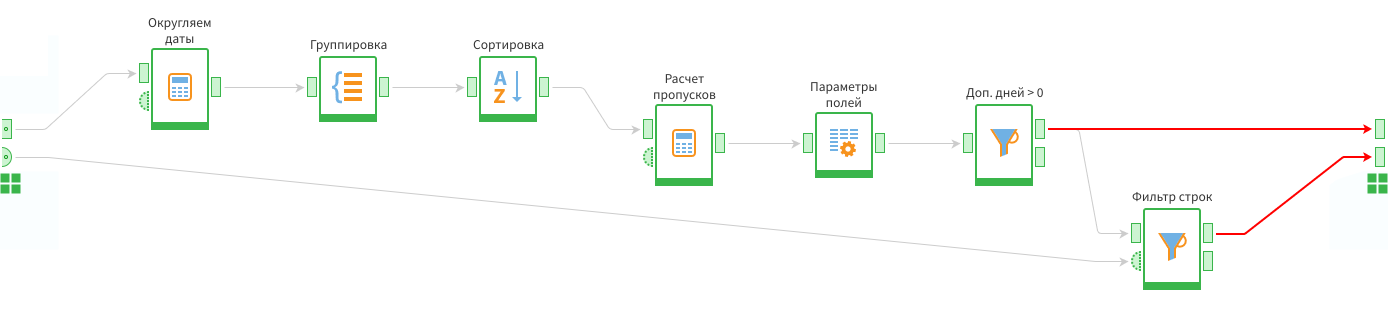
Вывод данных из подмодели
Таким образом был создан свой первый компонент, пригодный для переиспользования. Как его использовать, можно посмотреть в других пакетах и в инструкции по производным компонентам после занятия.
Для визуализации полученной таблицы надо добавить в подмодель определения пропусков визуализатор Диаграмма.
На ось X требуется перетащить поле Пропуск с, а поле Пропущено дней разместить в центре визуализатора, а затем выбрать вариант отображения Столбчатая диаграмма.
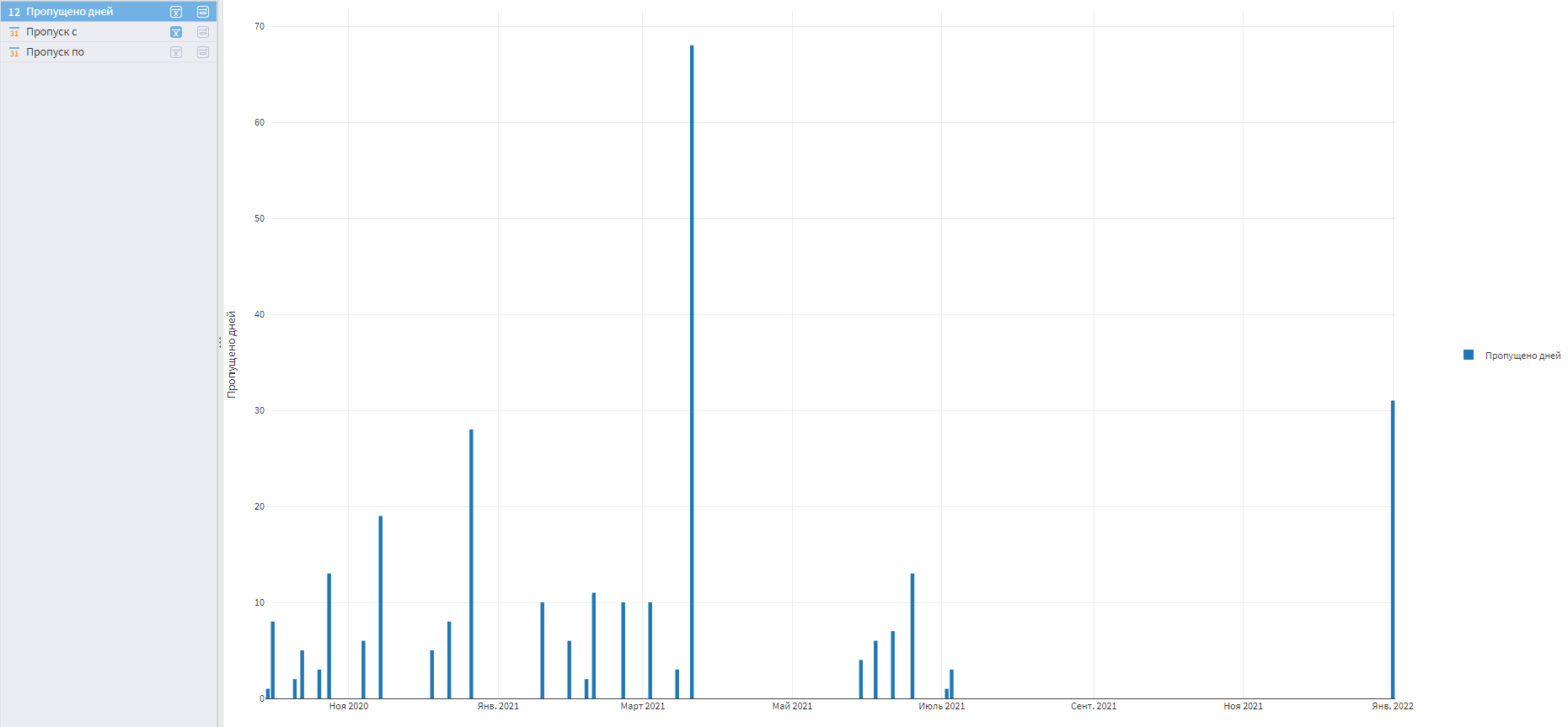
Визуализация пропущенных дней
По графику видно, что пропусков немало. В реальной жизни надо разбираться, в чем причина такого плохого качества. Вопросов может быть много:
Реальность обычно сурова: чем больше времени прошло с момента возникновения ошибки, тем сложнее ее исправить. Поэтому пропуски нужно мониторить на постоянной основе.
В нашем случае пропуски 2021 года восстановить не получится. Часть из них возникла из-за технических ошибок, а где-то продажи действительно отсутствовали.
Аудит пропусков наводит на мысль, что не стоит строить прогнозирующую и моделирующую аналитику на этих данных. Лучше считать клиентские портреты по данным за последний год.
Пропуски в относительно свежих данных чаще всего можно восстановить, но все равно нужно понять причину их возникновения, чтобы исправить брак. Чаще всего это ошибки в работе ETL-процесса. Поэтому предположим, что в новой базе ниже эта проблема устранена.
Для исправления ситуации нужно заменить файл базы в папке Data на новый, и повторно импортировать данные. После этого надо еще раз просмотреть график пропусков в январе 2022.
Работа с пропусками — деликатная тема. В зависимости от сценария анализа и критичности пропусков можно попытаться их восстановить, но иногда приходится оставлять как есть.
Независимо от выбранного подхода нужно проверять наличие пропусков и оповещать об этом коллег. Даже если данные так и остались с пропусками, наличие информации о том, что таковые в исходных таблицах имеются, позволяет делать более корректные выводы.
Часто решение проблемы исключения пропусков возможно на стороне систем учета и автоматизации. Нельзя рассчитывать, что задачу можно решить только за счет хитрых алгоритмов.
Как итог работы с пропусками можно заметить, что средняя прибыль и средний чек в портрете клиентов изменились. Вот значения до восстановления пропусков.
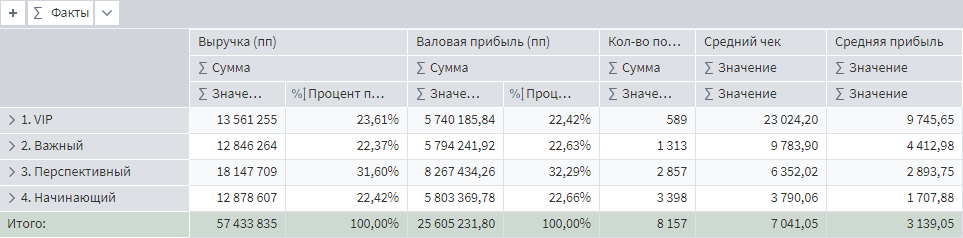
Портрет клиентов до восстановления пропусков
А вот, что получилось после.
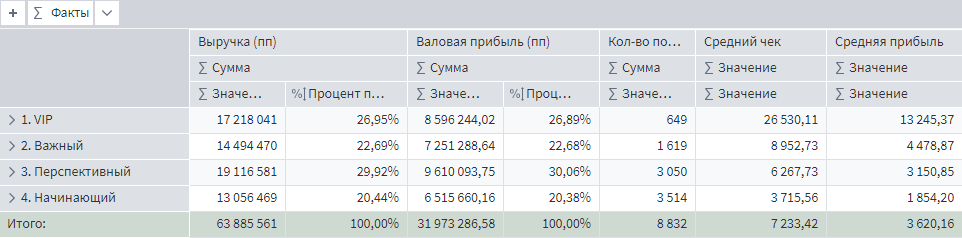
Портрет клиентов после восстановления пропусков
Средняя прибыль с продажи в категории VIP неплохо подросла, как и в сегменте перспективных клиентов. А значит дальнейшее планирование по работе с этими сегментами может быть пересмотрено.
Общий средний чек вырос, потому что добавлены пропущенные транзакции за январь 2022. Без этой операции средний чек бы снизился, т.к. при неизменной сумме продаж, увеличилось количество транзакций за счет восстановления номеров продаж.