
Есть такая категория ошибок, которая не выглядит как проблема с точки зрения визуализатора Качество данных. В то же время, это явление одно из самых популярных, оно почти всегда на слуху.
Речь, конечно же, про дубли!
История из жизни. Однажды один сотрудник крупной ритейловой сети делал систему автозакупок товаров. В расчетах что-то пошло не так, количество товаров заводилось многократно. В итоге вместо заказа нескольких мешков муки, закупили несколько вагонов. И вагоны приехали.
Директор бегал в бешенстве и кричал на несчастного сотрудника: «Ты что наделал, Ван-Дамм проклятый?» «А почему Ван-Дамм?» — грустно спрашивал виновный. «Да потому что ты нанес компании ДВОЙНОЙ УДАР!!!»

Дубли не выявляются в Качестве данных, потому что проверки этого визуализатора работают на уровне отдельных полей. А наличие дублей в одном поле — это не проблема, если только это не поле первичного ключа, который должен быть уникален в каждой строке. Но далеко не во всех таблицах такое поле формируется или выгружается.
Те дубли, о которых будет рассказано сегодня, проявляются на уровне строк, т.е. как сочетания значений нескольких полей в одной строке.
Поэтому для контроля дублей нужно применить другие инструменты. Таким образом, на любого двойного Ван-Дамма найдется свой Боло Йенг!

В 99% случаев дубли появляются по трем причинам:
Важно! Если вы не сделали практику в теме «Ты не пройдешь! Ловим ошибки данных на входе», то предварительно требуется открыть решение задания предыдущего дня, скачав его ниже.
lgpРешение практического задания. День 6.lgp
Если соединение таблиц выполняется в Loginom, то все просто — можно сравнить количество записей на выходных портах узлов до соединения и после.
Зайдите в подмодель Продажи и проверьте, увеличивается ли количество строк после слияний. Если да — значит в таблице возникли дубли.
Как видно по ролику, количество строк увеличивается после присоединения справочника клиентов. Почему это происходит?
Если изучить справочник клиентов, то можно обнаружить, что встречаются контрагенты у которых несколько юрлиц, а связываются таблицы по идентификатору клиента. При слиянии каждый клиент с несколькими юридическими лицами дублирует количество своих продаж столько раз, сколько у него юрлиц.

Это проблему можно решить с помощью узла Группировка, группируя только уникальные комбинации тех полей, которые требуются. При этом поля в область показателей можно не добавлять.

Надо добавить эту группировку после загрузки справочника клиентов, но до слияния с продажами. Полем Юрлицо жертвуем, потому что оно непригодно для аналитики с этим массивом данных.
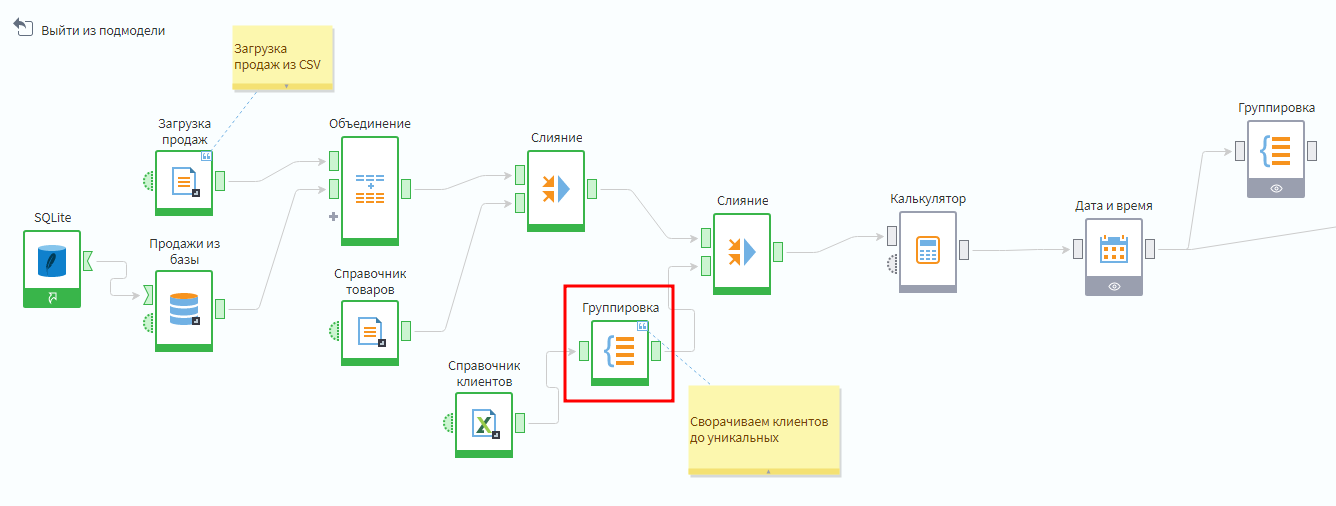
Добавление группировки в сценарий
Можно убедиться, что после группировки при слиянии продаж с клиентами количество строк в таблице не увеличивается.
Как быть с таблицами, которые мы получаем в готовом виде? Мы загрузили транзакции из CSV и базы данных без знания какой-либо предыстории их возникновения.
Может быть, это были таблицы которые мы сформировали сами, и знаем точно, что все нормально. А может — это вьюхи в хранилище, которые формировал неизвестный программист, который уволился 2 года назад. Лучшее, что можно сделать в этой ситуации, отталкиваться от подхода «доверяй, но проверяй». Если ошибки не будут обнаружены — хорошо, проверка повысит уровень доверия к анализируемой информации.
Надо добавить в сценарий узел Дубликаты и противоречия из группы Исследование. Затем подать на вход объединенную таблицу транзакций до присоединения справочников.
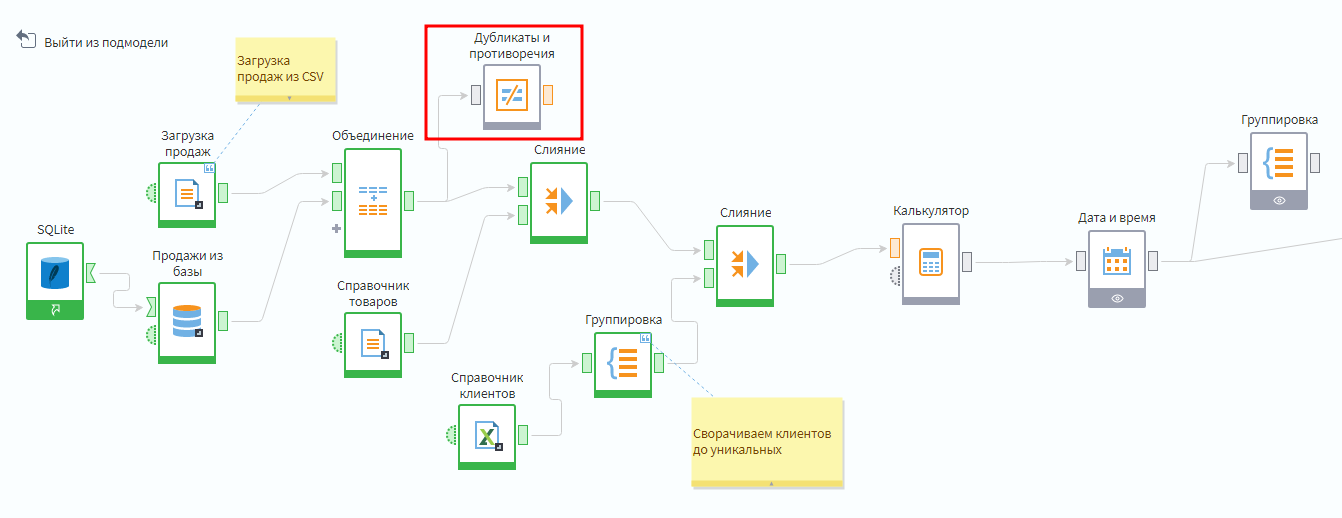
Добавление узла поиска дублей и противоречий
После запуска настройки узла видно, что в таблице транзакций нет поля, которое позволяет однозначно идентифицировать транзакцию, т.е. нет первичного ключа. Поле Номер чека не подходит, потому что оно дублируется, если в чеке несколько позиций.
Поэтому можно исходить из того, что в таблице не должно быть ни одной дублирующейся строки.
Для поиска дублирующихся строк надо все поля в настройках узла Дубликаты и противоречия определить как входные.

После активации узла нужно зайти в настройку его визуализаторов. Некоторые обработчики имеют свои особенные визуализаторы, и Дубликаты и противоречия — один из них. Надо перетащить визуализатор в область компонентов.

В визуализаторе Дубликаты и противоречия требуется отсортировать по убыванию группы дубликатов. Нужные строки отобразятся вверху таблицы.
Как видно на скриншоте, выявлено 280 270 групп дублей! Неплохой сюрприз от создателя таблицы.
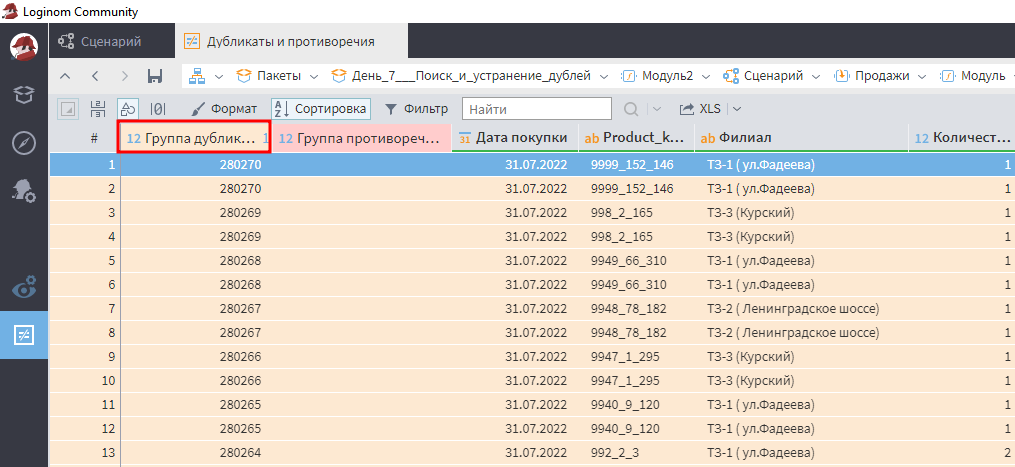
Группы дублей
Проблемы надо решать. Есть 2 варианта:
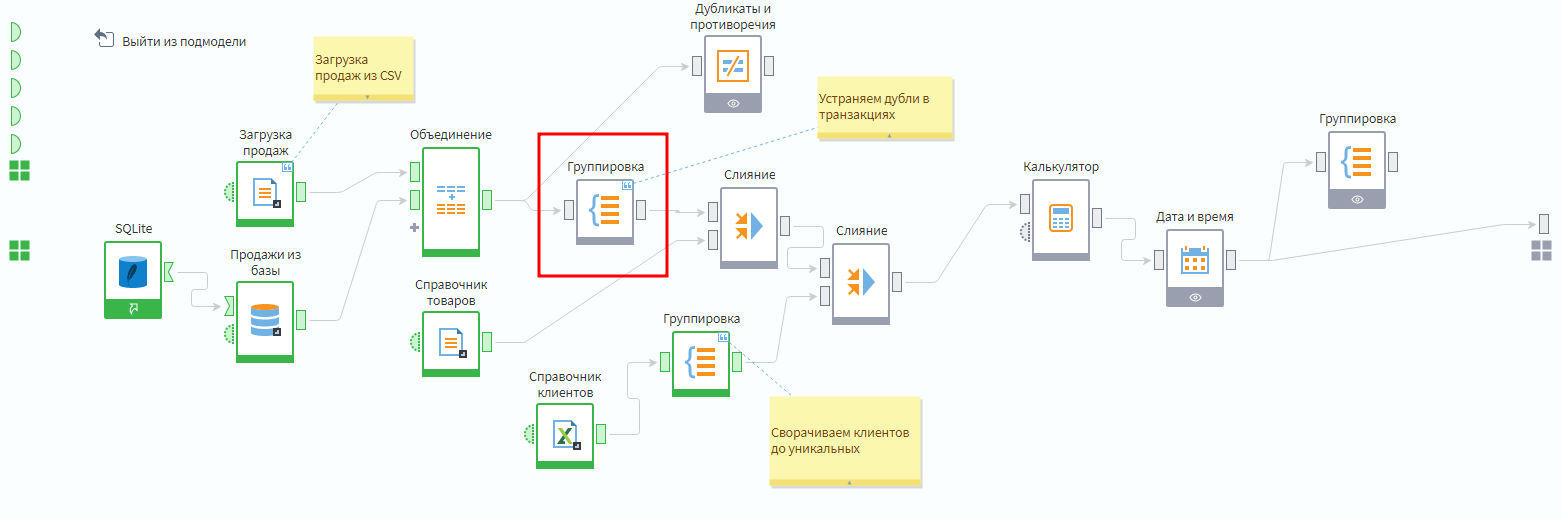
Исключение дублей
Возникает вопрос: насколько корректно для исключения дублей просто брать и группировать все поля транзакций?
Здесь потребуется понимание логики формирования документов. Если клиенту внесли несколько экземпляров одного и тоже же товара в один чек, то записи должны схлопнуться, а такие показатели, как Количество и Сумма покупки сложиться. Каждый товар в чеке должен быть уникальным.
Таким образом, возникновение 2-х одинаковых строк в этой таблице невозможно. Следовательно, повторяющиеся строки — это дубли, а не фактические продажи.
В реальных проектах надо убедиться, что логика формирования строк в таблице продаж такая, как описана выше. Только в этом случае можно использовать подобную группировку для исключения дублей.
В данных помимо дублей может быть и другой тип ошибок — противоречия. Он близок к дублям, но есть и отличия. Именно поэтому обработчик называется Дубликаты и противоречия!
Поиск противоречий — это такой вариант сканирования данных, когда обнаруживаются строки, у которых входные поля дублируются, а выходные — отличаются.
Проще всего это объяснить на примере.

В таблице поле Товар указано как входное, а поле Категория – как выходное. Т.е. для всех товаров с одинаковыми названием должна быть одна и так же категория.
Как видно, это справедливо для карандашей, все они относятся к категории товаров для рисования. Но в случае фломастеров имеются противоречия: одна запись отнесена к категории товаров для рисования, а вторая — детских игрушек. Такого быть не должно, данные противоречивы.
В общем случае входных и выходных полей может быть несколько. Таким образом, можно перефразировать так: противоречие — это когда одинаковому набору значений входных полей соответствует разные значения выходных.
Противоречия можно использовать не только для поиска технических ошибок, но и для выявления проблем в бизнес-логике.
Проверять данные на дубликаты рекомендуется в первую очередь, до того как наводить порядок по другим критериям. В зависимости от характера дубликатов проблема решается или группировкой данных на стороне Loginom, или устранением первопричины на стороне источника.
Задание №1. Устраните с помощью группировки всех полей дубли в таблице транзакций. В итоге из подмодели Продажи должно выходить 2 155 970 строк.
Задание №2. C помощью перенастройки узла Дубликаты и противоречия найдите все случаи, когда в один день на один адрес приезжали разные машины доставки. Будем считать, что это неэффективно с точки зрения логистики, поэтому такие случаи нужно выявлять для разбора.
Пример структуры итогового сценария:
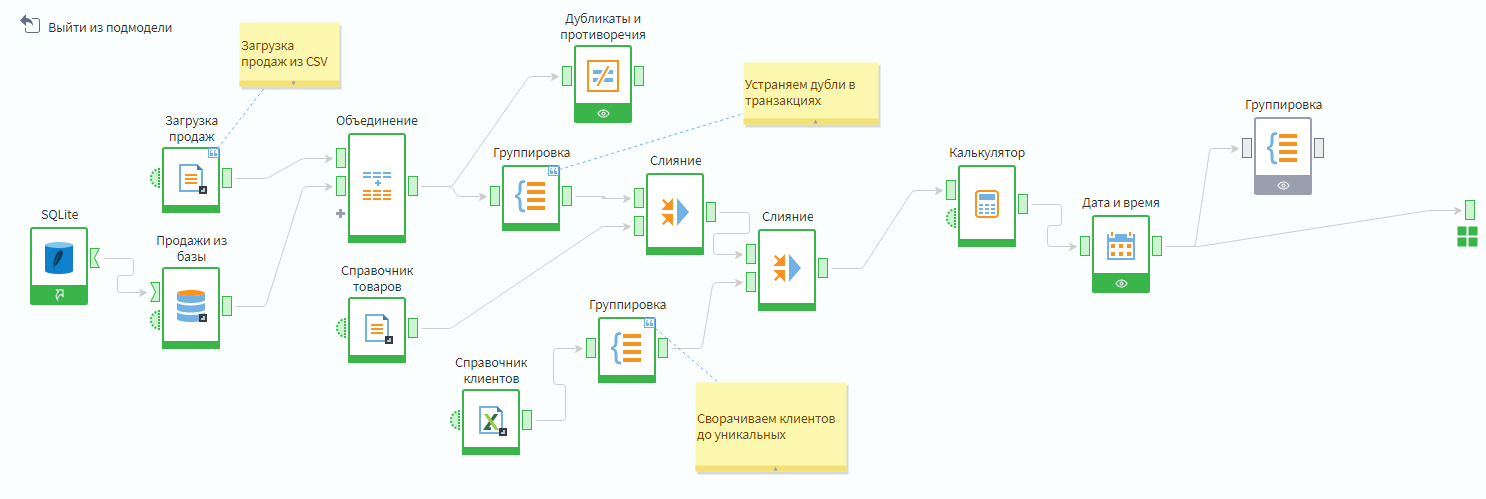
Итоговый сценарий
Может возникнуть вопрос: почему узел Дубликаты и противоречия висит как тупиковая ветка, а не стоит перед/после группировки? Ответ: для того, чтобы построение итоговой таблицы продаж не дожидалось выполнения проверки на дубликаты.
Посмотрите, как устранение дубликатов повлияет на портреты клиентов. Вот какой был профиль до их исключения.

А вот как стало после.

Ожидаемо, что значения выручки и валовой прибыли снизились. Но интереснее то, что в меньшую сторону изменились значения среднего чека и средней прибыли.
Почему так важен именно средний чек и средняя прибыль? Потому что эти показатели отражают качество клиентской базы. До устранения дублей значение данных характеристик было завышенным. Реальность оказалась суровее.
Слишком оптимистичные показатели создавали ошибочные предпосылки для дальнейших выводов по развитию клиентской базы.