
Любой человек, знакомый с маркетингом, понимает, насколько важно знать о своем клиенте как можно больше. Информация о его предпочтениях, особенностях поведения, пожизненной ценности, склонности к оттоку и любых поведенческих характеристиках способна в разы увеличить доходы компании или снизить издержки.
Можно попробовать собрать информацию о поведении клиентов за счет опросов или маркетинговых исследований, но это сложно, долго, дорого и ненадежно. Намного лучше извлекать инсайты из истории покупок. Покупки расскажут о клиенте очень много, даже то, что он сам про себя не знает.
Поэтому наша цель — создать таблицу с полезными поведенческими характеристиками клиентов, выходящими за рамки того, что можно получить при помощи простых отчетов. Очистка данных позволит увидеть реальную картинку, свободную от шума, мусора и случайных событий.
Важно! Если вы не сделали практику в теме «Импорт из баз данных на примере SQLite», то предварительно требуется открыть решение задания предыдущего дня, скачав его ниже.
rarРешение практического задания. День 4.rar
Сценарий должен быть более функциональным. Для этого нужно добавить приличное количество узлов, а даже текущий сценарий по ширине уже занимает весь экран.
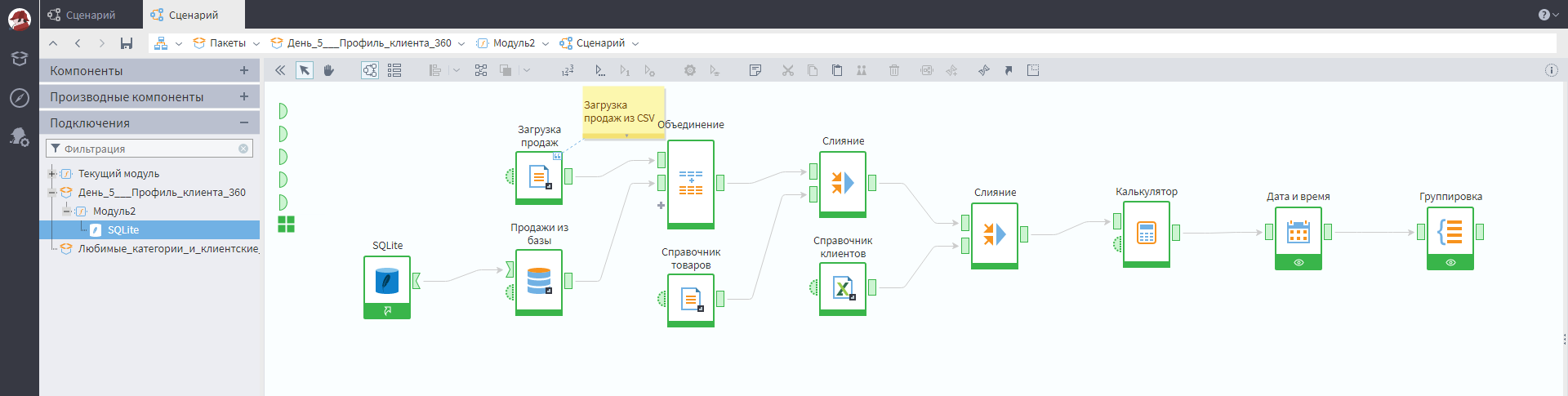
Можно продолжать достраивать его новыми узлами справа, технических ограничений нет. Но нужно принимать во внимание, что когда сценарий занимает больше одного экрана в ширину, работать с ним неудобно.
Поэтому начнем практику с оптимизации рабочего пространства. В предыдущие дни рассказывалось, что в Loginom существуют узлы, содержащие в себе другие узлы — это подмодели. Для большего удобства будет лучше, если мы свернем имеющийся сценарий в такую подмодель. Можно сразу задать ей название Продажи.
Если вы промахнулись при выделении всех узлов, и в подмодель свернулась только часть сценария, то вам нужно развернуть полученную подмодель и повторить процесс уже со всеми узлами.
В отношении подмоделей действуют те же правила ввода-вывода данных, что и у обычных узлов. Хотите ввести данные в подмодель – нужны входные порты. Хотите вывести — нужны выходные порты. А в результате свертывания получилась подмодель без портов, словно чемодан без ручки.

Давайте разберемся. Входные порты в этой подмодели не нужны — данные зарождаются у нее внутри через узлы импорта. А вот выход нужен, т.к. требуется производить дальнейшую обработку этих данных. Чтобы решить проблему, зайдем в настройки узла подмодели.
Здесь можно указать перечень входных и выходных портов, а также их типы. Сейчас нужен один табличный выходной порт.

При создании нескольких портов на вход/выход обязательно давайте им понятные названия. Это упростит работу со сценарием и сэкономит в будущем много времени. Имя показывается во всплывающей подсказке при наведении мышки на порт. Правильное название позволит сразу понять назначение данных без погружения в подмодель.
Порт появился, но он красный. Причина в том, что не определено, какие данные на него выводятся.

Зайдите внутрь подмодели и протяните связь между портом узла Дата и время и выходным портом подмодели.
Если вы сделали задание со звездочкой из дня 3, обратите внимание, что на выход надо подавать данные не с последнего узла Группировка, а из узла Дата и время, потому что нам нужны на выходе транзакционные данные. А в группировке у нас просто суммы продаж по месяцам.
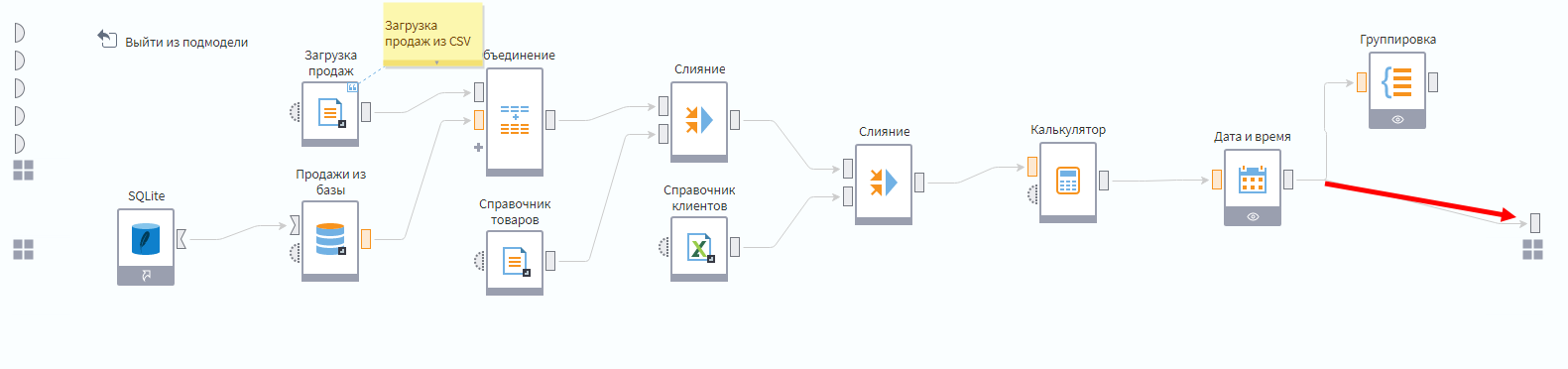
Теперь при активации узла подмодели спустя некоторое время на выходном порту будут данные с объединенной историей продаж.
Как сказано выше, задача — получить справочник клиентов с расширенными аналитическими признаками, отсутствующими в сводном отчета на исходных данных.
Благодаря ему можно определить проблемы и точки роста в клиентской базе. В нем будут количественные и качественные атрибуты. Часть из них будет считаться на всех доступных данных, а другая — на данных за определенный период.
Давайте же начнем!
В качестве основы этого супер-справочника понадобится список всех клиентов и их идентификаторов. Заодно можно добавить в него несколько аналитических признаков на основе всех доступных данных. Удобнее всего сделать это с помощью узла Группировка из набора узлов Трансформация. Перенесем этот компонент в сценарий после подмодели.

Зайдем в настройки группировки. Этот узел позволяет вернуть агрегированные значения полей показателей в разрезе группируемых полей. Добавьте в группируемые поля Client_ID как уникальный идентификатор и ключевое поле, если нам понадобится что-то связать с этой таблицей. Также добавьте в группы поле Покупатель, чтобы у нас было под рукой человекопонятное название клиента.
В показатели добавьте Сумма покупки, Валовая прибыль, Дата покупки.

Для Суммы покупки и Валовой прибыли Loginom автоматически предложит тип агрегации Сумма, и это нас устраивает. А вот Дату покупки надо поднастроить. Дважды кликните по показателю Дата покупки.
Откроется окно настроек, в котором надо задать способ агрегации по полю. Можно выбрать несколько вариантов. Нас интересует Минимум (дата первой покупки) и Максимум (дата последней покупки).
Интересный факт: для разных типов данных доступны разные способы агрегации.

Назовите этот узел LTV (Life time value) и активируйте его. На выходе должна быть таблица 3184 строки. Можно проверить это, дважды кликнув по выходному порту Группировки.
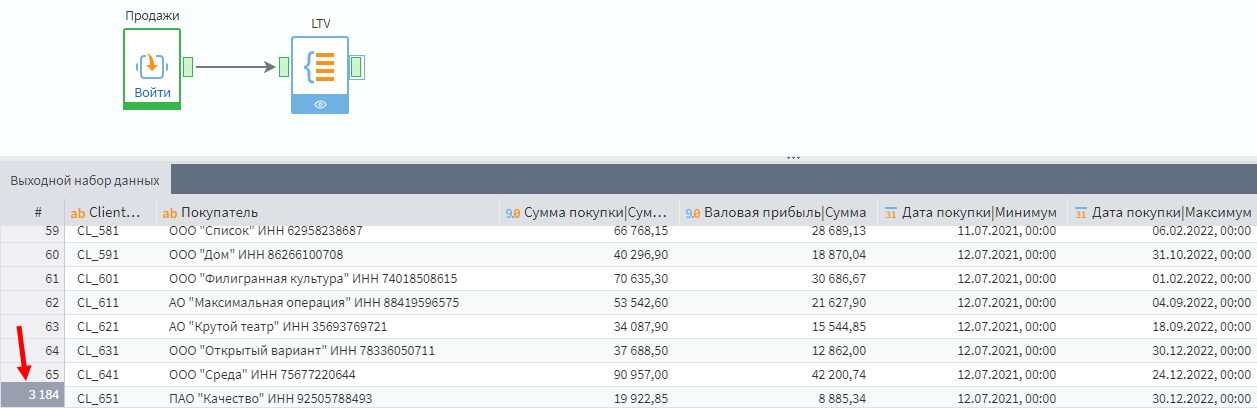
Просмотр результатов группировки
Выглядит неплохо, но у полей не очень красивые метки. Давайте это исправим.

В Loginom существует множество способов изменить названия и метки полей в ходе сценария. Самый простой из них — использовать обработчик Параметры полей из набора Трансформация.
Добавьте его в сценарий и заведите с него выход из LTV-группировки. Зайдите в настройки узла. Откроется список для настройки полей.

Дважды кликните по полю Суммы покупки. В появившемся окне настройки можно изменить метку, имя и тип данных поля. Задайте полям следующие метки:
Итог будет выглядеть так:

Галочкой Исключить справа можно выбрать поля, которые не будут передаваться на выход узла. Сейчас это не нужно, но в будущем может потребоваться.
Мы подготовили набор с самыми базовыми характеристиками клиентов. Однако в реальности такие таблицы содержат десятки полей. Чтобы немного срезать путь и заодно попробовать очень важный функционал Loginom, обратимся к механике производных компонентов.
Помните подмодели для ABC-анализа во втором дне марафона? Там эти узлы были частью сценария, и использовалось копирование, чтобы создать 2 ветки ABC-анализа: по товарам и по клиентам. Т.е. каждая подмодель была отдельной сущностью, их можно было независимо редактировать, а применение в других местах было возможно только через механику «копировать-вставить».

Механика производных компонентов позволяет использовать в текущем сценарии ссылки на подмодели, которые находятся в другом модуле или даже в другом пакете. Для этого нужно добавить ссылку на пакет, содержащий подмодели, которые мы хотим подключить.
Создайте в рабочей папке марафона папку Libs. Скопируйте в нее пакет ниже.
lgpЛюбимые категории и клиентские показатели.lgp

Заводить отдельную папку для пакетов-библиотек компонентов — это хорошая практика.
Давайте подключим этот пакет. Для этого зайдите в раздел Ссылки рабочего пакета. Это удобно сделать через строку навигации.

Нажмите на кнопку Добавить, укажите путь к пакету в папке Libs. После добавления он должен отобразиться в списке.

Вернитесь обратно в сценарий. В левой секции с библиотекой компонентов выберите раздел Производные компоненты. Разверните в нем раздел Любимые категории и клиентские характеристики. Там будет 2 компонента, которые вы можете добавить в сценарий.

Добавьте оба узла в сценарий.

В целом узлы производных компонентов работают аналогично обычным узлам. У них есть входы и выходы. Логика действий узлов определяется их внутренним сценарием. Настройки узлов обычно происходят через порт переменных.
Чаще всего узлы производных компонентов имеют входной порт с отключенной автосинхронизацией (точка на порту). Это значит, что в сценарий внутри узла поступают не любые поля, а только заранее определенные, вокруг которых построена внутренняя логика узла. Согласитесь, это не совсем логично, если в узлы с предопределенной логикой работы подаются любые поля без разбора.
Узел профиль продаж рассчитывает ряд характеристик по клиенту в разрезе клиентов за определенный период:
Вначале нужно подать данные в подмодель. Протяните связь между выходом из подмодели Продажи до входа в Профиль продаж.

Дважды кликните ЛКМ по входному порту данных у Профиля продаж. Будут отображены 4 поля. Это те поля, которые предопределены для использования в подмодели.
Для большей ясности включите режим отображения Связи в переключателе над таблицей. Отобразится 2 списка: поля таблицы, которую вы подали на вход в левой части, и поля, которые ожидает на вход подмодель в правой части. Нажмите кнопку Упорядочить связи, чтобы сделать картинку нагляднее.

Loginom старается определить соответствие полей, и если оно выглядит так же, как на картинке выше, — значит, все верно. Иначе нужно удалить неправильные связи и задать правильные. Как это сделать, показано на видео.
Активируйте узел после настройки связей. На выходе будет таблица с показателями, рассчитанными в разрезе идентификаторов клиентов.
Дважды кликните по входному порту переменных (полукруглый порт) подмодели Профиль продаж. Здесь задаются настройки производного компонента.
В этом порту можно настроить 2 переменные:
Посмотрите на выходной порт переменных в подмодели Профиль продаж (при необходимости, активируйте ее повторно).
В такие порты могут выводиться как переменные для использования в других узлах, так и справочная информация для понимания, что происходило внутри подмодели.
Здесь видно, что дата сегментации определилась как 31.12.2022 — это конечная дата в нашем наборе данных. А начальная дата (vMinDate) определяется как 31.12.2021. Эта переменная создана внутри подмодели, как разница конечной даты и глубины сегментации.
Если хочется, чтобы начальная дата была 01.01.2022, то это можно сделать, изменив на входном порту переменных глубину на 364 дня. Давайте сделаем это.
Имена полей, выходящих из подмодели, имеют метку _pp
Теперь, настроим вторую подмодель. Но возникает вопрос: переменные всегда надо задавать вручную?
Ответ: нет, можно реализовать динамическое определение переменных, например, через узел Калькулятор переменных. В нем задаются значения переменных с помощью любых функций, которые можно передать на вход подмодели.
Эта подмодель вернет список любимых категорий в разрезе по клиентам. Подключите связь от подмодели Продажи к входному порту узла Любимые категории.

По двойному клику ЛКМ по входному порту данных на узле Любимые категории будет предложена настройка порта. Надо убедиться, что поля сопоставлены как на картинке.

Кстати, если в поле Категория продукции подать, например, поле Бренд — то получится определение любимых брендов по клиентам. Так это сработает и с товаром. Но пока остановимся на категориях.
Зайдем в настройки входного порта переменных. Первые 2 нам уже знакомы — это дата построения сегментации, которую можно оставить пустой, и глубина сегментации в днях, которую нужно выставить как 364.
А вот последние 2 настройки — новенькие.

Переменная Чувствительность, % определяет, начиная с какой доли оборота клиента за период категория будет считаться любимой. Т.е. в любимые попадут только те категории, доля оборота по которым не меньше указанного числа.
Макс. кол-во категорий — сколько любимых категорий может быть. Категории выбираются в порядке убывания оборота. В целом эти настройки устраивают, но можно с ними поэкспериментировать.
Активируйте узел. Обратите внимание, что из подмодели Любимые категории есть 2 табличных выхода. Это пример того, что одна подмодель может возвращать несколько разных структур данных.
Так, из первого порта данные выходят в свернутом по клиентам виде: одна строка соответствует одному клиенту, а любимые категории свернуты в одну строку через разделитель. При этом категории расположены по убыванию «любимости».
Такой формат удобен для использования в обогащении справочника, т.к. на каждого клиента приходится одна строка данных, и при объединении с основным справочником строки не задвоятся.
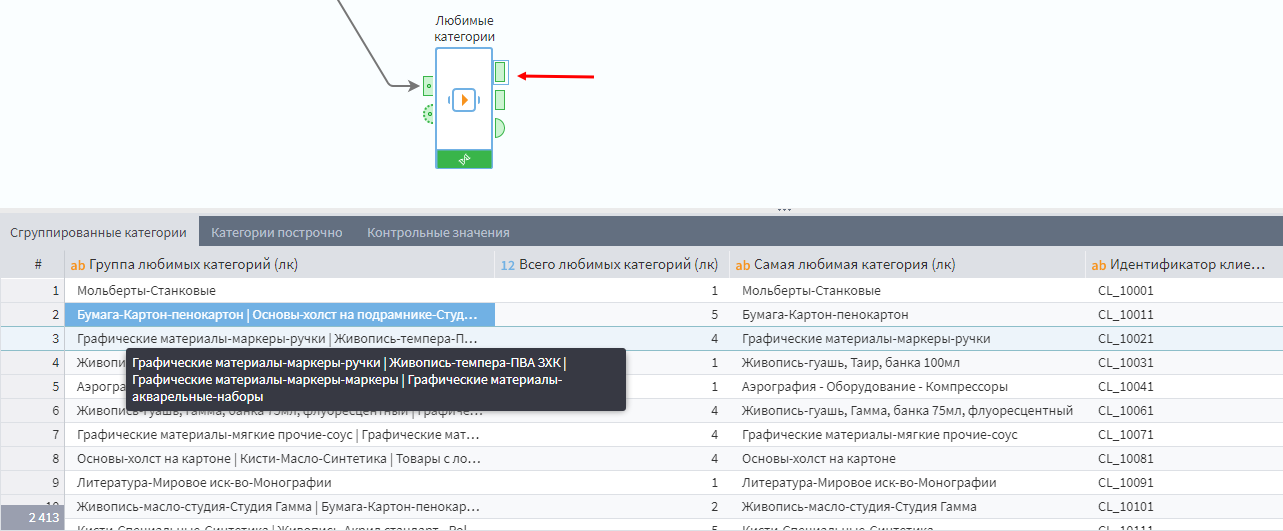
Из второго порта данных выходит массив, развернутый по строкам. Такой формат может быть удобен для передачи системам, которым требуется структурированный формат данных. Или для построения сводного отчета.
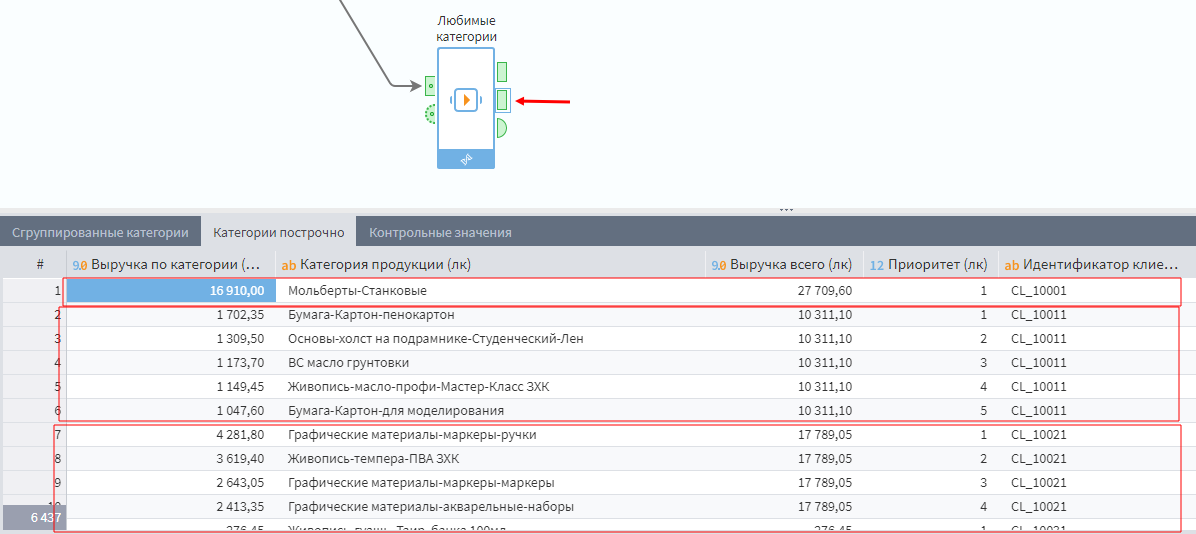
Имена полей, выходящих из подмодели, имеют метку _fc.
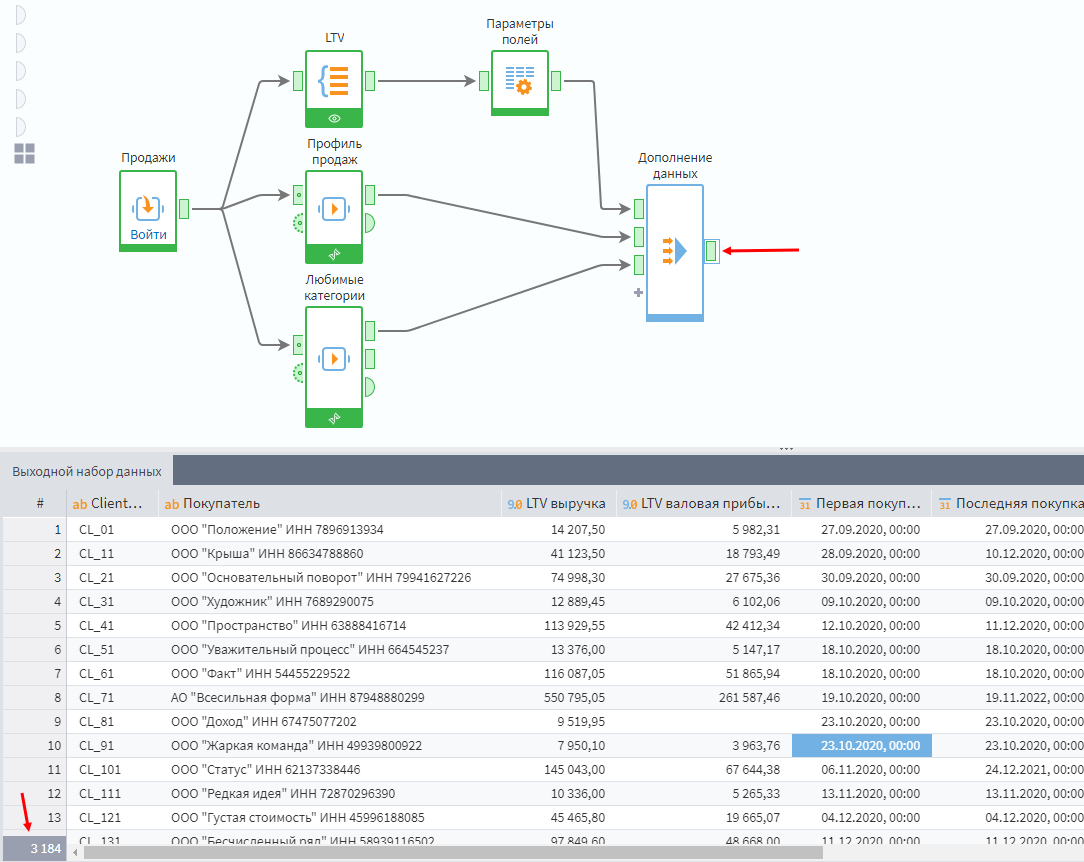
Формирование клиентских характеристик происходит в 3-х ветках сценария. Надо соединить их в единый справочник. Ранее аналогичная задача решалась за счет использования нескольких узлов Слияние. В этот раз будет использоваться компонент Дополнение данных из группы Трансформация.

Он позволяет соединить сразу несколько таблиц, но по сравнению с узлом Слияние, у него есть ряд ограничений:
Этот узел нужно использовать, когда требуется сделать Left join’ы к одной таблице нескольких других таблиц. В настройках узла выставим присоединение к Client_ID полей Идентификатор клиента из 2-х других таблиц.

Как итог, получится объединенный справочник на 3184 клиента.
У нас появился обогащенный клиентский справочник с большим количеством параметров. Однако анализировать голые числа неудобно. Есть смысл создать несколько дополнительных аналитических признаков, которые можно использовать как разрезы для отчетов и фильтры для быстрых отборов разных зон интереса в клиентской базе.
Для этого добавим в сценарий Калькулятор после блока Дополнение данных.

Для начала в настройках Калькулятора, создадим поле Дней с продажи. Дадим ему имя Days_from_sale. Т.к. в наборе есть поле Data_pokupki_Max, то формула today()-Data_pokupki_Max вернет количество дней, которые прошли с последней продажи до сегодняшнего дня.
Но т.к. у нас статичный учебный датасет, сделаем дату условного сегодняшнего дня тоже статичной. Чтобы дальнейшие изменения в данных происходили от наших действий, а не потому что часики тикают.
Для этого можно использовать функцию EncodeDate. Она трансформирует значение года, месяца и числа в дату. Очень полезная формула, когда надо сделать распознавание данных в дату, или задать ее статичное значение.
В результате формула дней с последней продажи будет выглядеть следующим образом: EncodeDate(2022,12,31)-Data_pokupki_Max.
Теперь внедрим параметр, который будет определять качество клиентского поведения. Нужно понимать, находится ли клиент в своем стандартном графике закупок или начинает уходить. Самый простой способ это выяснить — посчитать разницу между средней периодичностью покупок и количеством дней с последней продажи.
Для этого создадим текстовое поле Client_status (Статус клиента). Способов расчета статусов много, но в этом примере будет использоваться следующий:

Формула будет иметь следующий вид:
if(isnull(Transactions_pp),"5. Прекратил работу", if(Transactions_pp=1,"1. Разовый", if(Days_from_sale-Sales_freq_pp<=10,"2. Рабочий клиент", if(Days_from_sale-Sales_freq_pp<=20,"3. Теряемый клиент","4. Потерянный клиент"))))
Обратите внимание, что в формуле есть ссылка на ранее вычисленное поле Days_from_sale. Это сделано, чтобы упростить синтаксис выражения.
Теперь понятно, кто из клиентов работает с нами в обычном режиме, а кто уходит. Но чтобы планировать какие-то действия с базой потребуется некая система приоритетов — в первую очередь стоит работать с самыми важными покупателями.
Очень удобно определить это на основе количества денег, которые клиент принес в компанию. Это можно сделать на основе поля Revenue_LTV. Создадим поле Client_level (Уровень клиента).

Формула будет такая:
if(Revenue_LTV>=200000,"1. VIP", if(Revenue_LTV>=75000 and Revenue_LTV<200000,"2. Важный", if(Revenue_LTV>=25000 and Revenue_LTV<75000,"3. Перспективный","4. Начинающий")))
В заключение понадобится еще один параметр, который поможет лучше определять приоритетность взаимодействия с клиентами. Это классификация на основе давности последней продажи.
Согласитесь, что намного перспективнее контактировать с клиентами, которые покупали что-то в предыдущие пару месяцев, чем с теми, кто в последний раз что-то брал более года назад.
Логика будет простая: если покупал до 90 дней, то клиент действующий, если до 180, то приостановленный, а если больше 180 — значит забытый. Формула получается такая:
if(Days_from_sale<90,"1. Действующий", if(Days_from_sale>=90 and Days_from_sale<180,"2. Приостановленный","3. Забытый"))

Мы проделали большую работу. Теперь есть справочник клиентов, обогащенный статистическими и управленческими атрибутами. С таким массивом можно не просто смотреть на исторические данные, но и принимать решения и действовать на опережение для устранении рисков, например, потерь клиентов.
Чтобы это стало возможным, остался последний штрих — сделать отчет, позволяющий находить точки интереса.
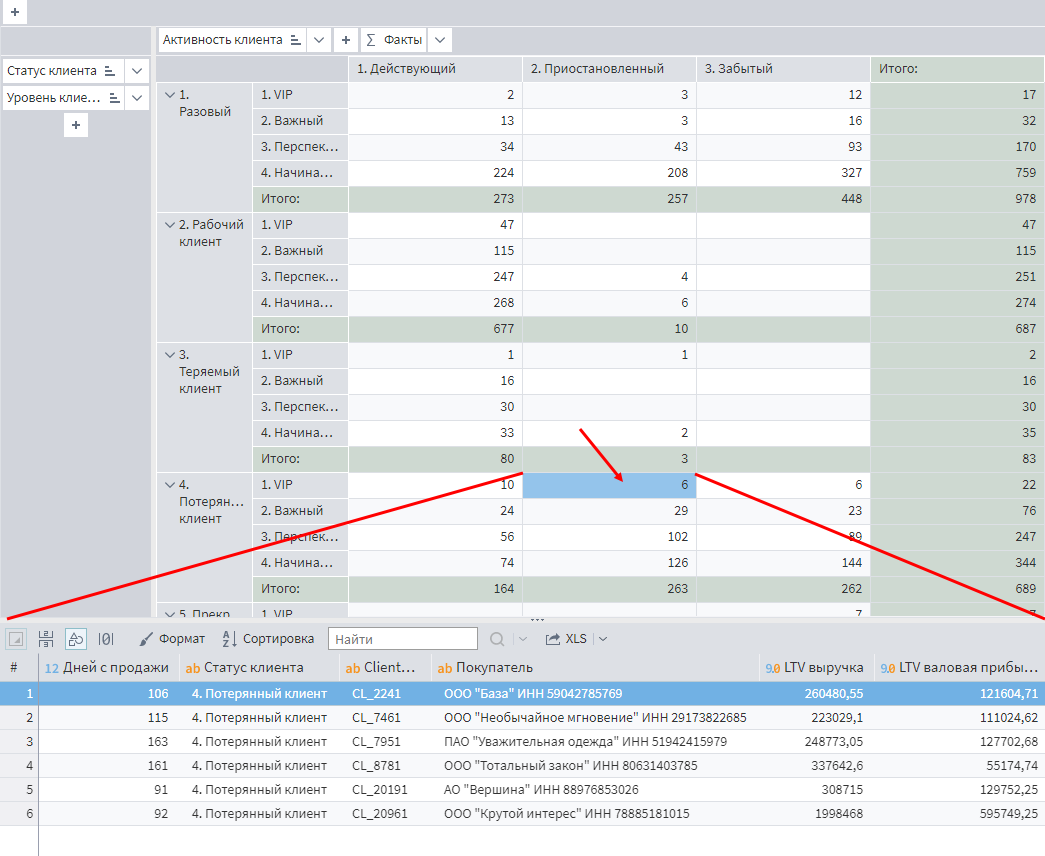
Задание №1. Сделать отчет по сегментам клиентской базы.
Добавьте визуализатор Куб в финальный узел Калькулятор сценария и назовите его Сегментация клиентов.
Добавьте в строки разрезы Статус клиента еще поле Уровень клиента, в столбцы — Активность клиента, а в качестве показателей — количество уникальных значений поля Client_ID.
Результат должен выглядеть вот так.
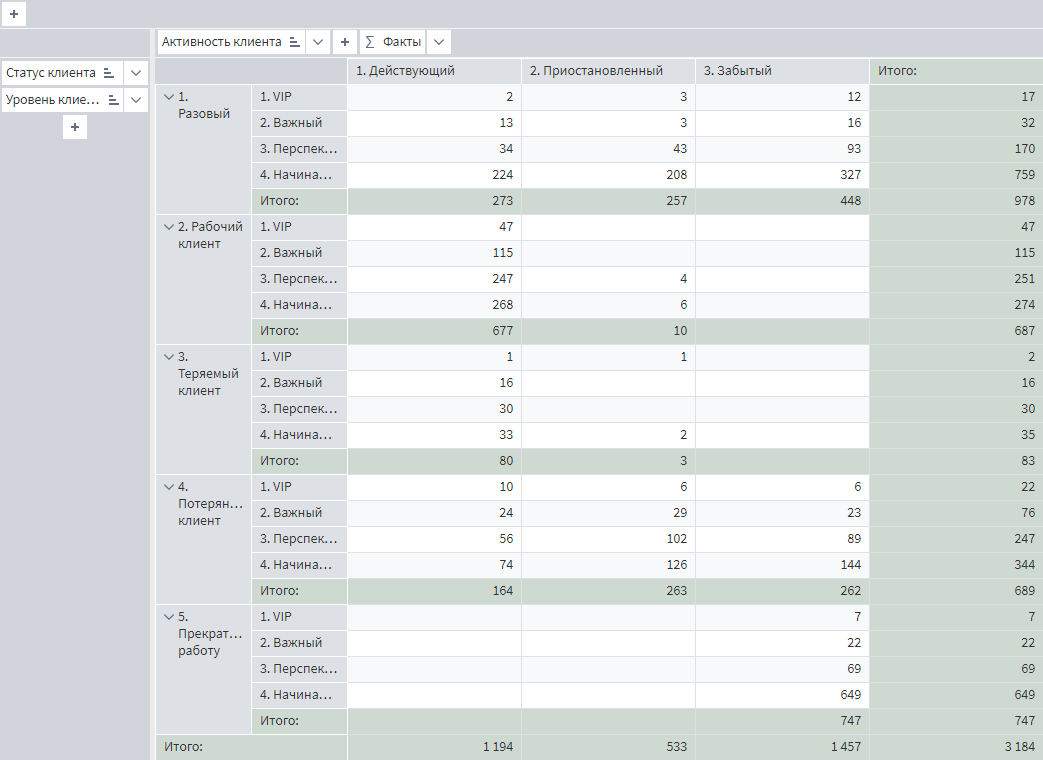
Активируйте на панели инструментов детализацию.

Покликайте по разным ячейкам таблицы и посмотрите, как строки, образующие данное число, выводятся внизу. Как несложно догадаться, так можно легко получить различные списки клиентов с потенциалом на реанимацию или допродажи.
В таблице также содержится информация о товарных предпочтениях клиентов, что поможет завязать диалог или составить предложение заранее. Эта информация может быть выгружена в Excel как в ручном, так и в автоматическом режиме. Либо передана в другие системы.
Задание №2. Оценить финансовую привлекательность.
Создайте второй визуализатор Куб в узле Калькулятор и назовите его Портрет клиента. В качестве разрезов строк добавьте поле Уровень клиента. В качестве показателей используйте:
Важно! Пункты 4 и 5 решаются с помощью функционала Вычисляемый факт.
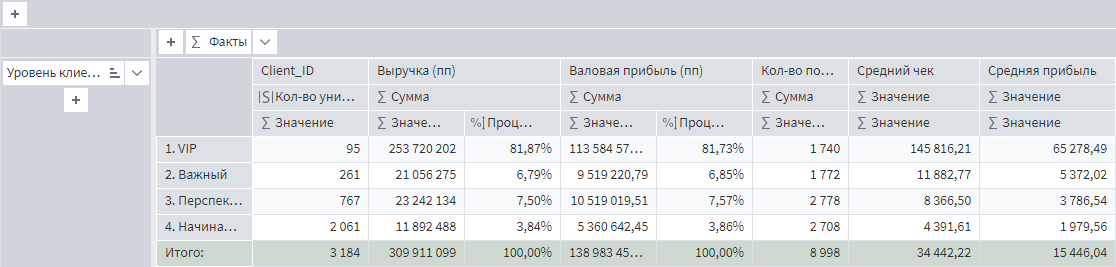
Эту таблицу можно использовать для того, чтобы определять, что клиент представляет из себя в финансовом эквиваленте. Видите ли вы сейчас что-то подозрительное здесь?
Такую информацию надо использовать для задач финансового моделирования и прогнозирования. Поэтому цель подобных отчетов — не просто показать, что есть данные, а выдать некую картину, которая будет максимально приближена к действительности. Потому что неверные оценки приведут к заниженным/завышенным прогнозам и планам, создадут неадекватные финмодели и пустят компанию по ложному пути.
В отличие от отчетов, просто визуализирующих факты, здесь нужно чистить данные не только технически, но и по смыслу. График продаж показывает в прошлом месяце рекордные прибыли — это факт. Но будет ли такая динамика роста всегда? Или вчера закупился один клиент, который раз в 2 года делает мега-закупку, и компании в своих планах нужно ориентироваться на другой тип клиентов?
Как решать такие вопросы и обходить ловушки, разберем в следующих днях ;)
Получить разборы домашних заданий
У Юлии Счастливой более 20 лет опыта работы в управлении продажами и выстраивании новых направлений в компаниях, с управлением структурами до сотни сотрудников. Конечно же, эта работа невозможна без качественной аналитики. На эфире Юлия делится некоторыми тонкостями анализа клиентских баз для B2B. А именно, как быстро начать определять точки роста с минимальными усилиями с точки зрения аналитики.