
Сегодня начинается практическая работа с Loginom. Шаг за шагом будет выстроен сценарий оценки и улучшения качества данных для последующего поиска точек роста в клиентской базе. В процессе работы мы избавимся от ряда ошибок, которые заботливо заложены в учебный датасет ;)
Информацию и шаги будем давать порционно, чтобы избежать перегрузки. Поэтому если вдруг увидите в данных что-то странное, а мы об этом никак не обмолвились — не паникуйте, все еще впереди. Своими подозрениями обязательно делитесь в telegram-чате. Проверим, какие проблемы в данных легко определяются на глаз.
Исходный датасет состоит из 3-х таблиц:

Несмотря на существование множества СУБД и всевозможных API, загрузка данных из файлов остается одним из самых распространенных сценариев. В конце концов, даже если в компании есть настроенное хранилище данных, нет гарантий, что завтра не придется анализировать эту информацию вместе с какой-нибудь выгрузкой из базы таможни. Поэтому начнем с импорта данных из файлов.
Создайте на диске в удобном месте папку с любым названием (например, Марафон Loginom 2023). Это будет рабочей папкой марафона. Скачайте учебные данные. zipДанные для практики. День 3.zip Разместите учебные файлы так, чтобы они находились в рабочей папке марафона в папке Data.
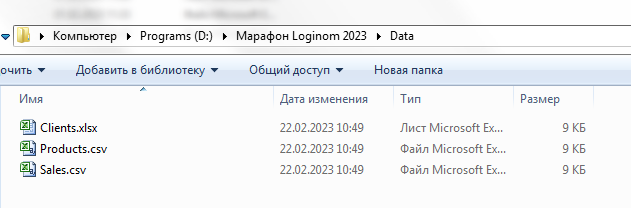
Такое расположение папок важно для легкого использования демонстрационных пакетов, т.к. по умолчанию в узлах импорта файлов прописываются относительные пути.
Откройте Loginom и создайте новый пакет. Вы можете назвать его как угодно. Самое главное — создать пакет внутри рабочей папки марафона, чтобы он лежал рядом с папкой Data.
В итоге в рабочей папке марафона должна получиться следующая структура:

После создания пакета в Loginom будет отображен пустой сценарий.

Сначала данные должны быть загружены в Loginom. За это отвечают узлы из группы Импорт, которая находится в самом верху панели компонентов. Как можно заметить, анализируемые данные представлены двумя CSV-файлами и одним файлом Excel.
Начнем с импорта CSV. За него отвечает компонент Текстовый файл. Его надо перетащить из левой панели в пространство сценария.

Затем узел необходимо настроить. Щелкните ЛКМ в его центре, чтобы появились пиктограммы управления узлом. Щелкните по шестеренке, чтобы перейти в настройки узла.

Настройки узла импорта осуществляются в несколько шагов. На первом нужно указать путь к файлу и определить его кодировку. Укажите путь к файлу Sales.csv в папке Data. Правильная кодировка — UTF-8.
На этом этапе можно включить определение заголовков полей по первой строке и задать количество пропускаемых строк сверху. Это требуется, когда данные начинаются не с первой строки или в таблице есть шапка с ненужной информацией.

Предпросмотр покажет, как Loginom считал содержимое файла. На этом этапе не заданы разграничители, и важно проверить, что в тексте нет «кракозябр». Это значит, что кодировка настроена правильно.
На втором шаге импорта размечается структура загружаемой таблицы. При импорте из текстовых файлов нужно задать настройки разделителей и ограничителей строк, чтобы данные не «поплыли» в итоговой таблице.
История из жизни. При неправильно определенных разделителях и ограничителях можно обнаружить, что в некоторых строках перепутаны значения полей. Например, в названии клиента отображается сумма продаж. Но это не самый страшный случай — такую проблему легко распознать при дальнейшей обработке.
Намного неприятнее то, что с неправильными настройками некоторые строки могут просто не прогрузиться, при этом структура таблицы останется неизменной. В свое время было потрачено много часов на поиск такой ошибки в одном проекте. Лайфхак: если при импорте из CSV получается меньше строк, чем в исходном файле, стоит проверить настройки разделителей и ограничителей.
Иногда проблема может быть не в неправильных настройках, а в том, что в данных содержится символ, срабатывающий как разделитель. Например, разделителем в файле является «;», но также такой знак содержится в значении какого-нибудь поля, типа компании с названием «Супер бизнес; не звонить!».
Если значение в поле названия компании не экранировано ограничителями (двойными кавычками, например), то этот символ будет учтен как разделитель и сломает таблицу. Наличие подобного экранирования зависит от настроек системы, из которой выгружается CSV файл. Это стоит учесть при формировании выгрузок.
Если нет уверенности в правильности настроек, можно нажать на кнопку Определить автоматически. Loginom достаточно точно определяет структуру файла самостоятельно. Кстати, нажмите ее на всякий случай.
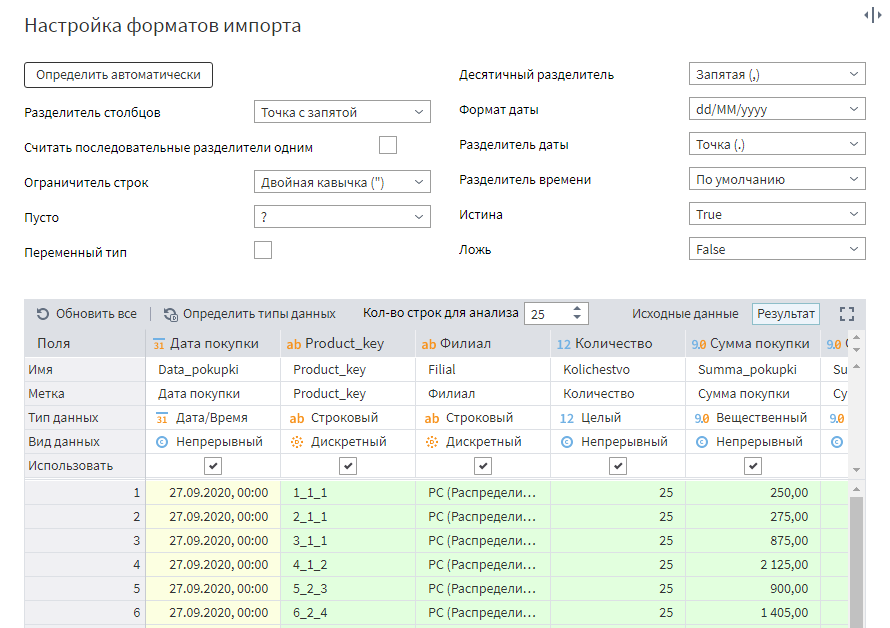
Внизу отображается таблица, которую Loginom распознал. Здесь можно провести дополнительную настройку полей. Что тут интересного?
Во-первых, наименование полей в Loginom определяется двумя параметрами:
Автоматически определенные имена и метки нас полностью устраивают — нет необходимости их менять.
Во-вторых, требуется настройка типа и вида данных. В Loginom используется строгая типизация, следовательно, нужно для каждого поля определить, данные какого типа в нем находятся.
От этого зависит, какие методы обработки и трансформации Loginom сможет применить к полям, и в какой роли он их сможет использовать.
Доступны следующие типы данных:
В зависимости от выбранного типа данных значения в полях подсвечиваются зеленым, желтым или красным цветом.

Это экспресс-проверка на соответствие значения выставленному типу данных:
Попробуйте выставить полям разные типы и посмотреть, как реагирует проверка соответствия.
Когда наэксперементируетесь, верните все как было с помощью кнопки Определить автоматически слева вверху.
Параметр Вид данных имеет 2 значения: непрерывный или дискретный. Если задать непрерывный, то в некоторых функциях Loginom будет оценивать значения поля как последовательные значения одной оси (например, дата и время).
В частности, будет возможность искать пропуски в диапазонах значений в таких полях. Дискретный вид означает, что каждое значение — это просто отдельное значение. Например, номер чека, который может быть числовым, но при этом арифметические операции с ним лишены смысла.
Для выполнения настроек на этом экране достаточно нажать кнопку Определить автоматически. Сделайте это и двигайтесь на следующий шаг. Вы увидите экран Настройка соответствия между столбцами. Если кратко, то здесь определяется, какие поля покинут узел, и как они будут называться.
Для учебного примера этот экран не важен. Можно убедиться, что набор полей, их названия и типы данных соответствуют тому, что на картинке, и двигаться дальше.
Финальный этап настройки — присвоение метки узлу и опциональное добавление комментария.

Этот текст будет отображаться в схеме сценария. Поэтому рекомендуется добавлять подписи для улучшения читабельности.

Кстати, менять подписи узлов, как и комментарии, можно через двойной клик ЛКМ по ним. Комментарии можно скрыть через клик по знаку кавычек в правом верхнем углу узла. Быстро добавить/удалить комментарий к узлу можно через контекстное меню, которое открывается по клику ПКМ на узле.

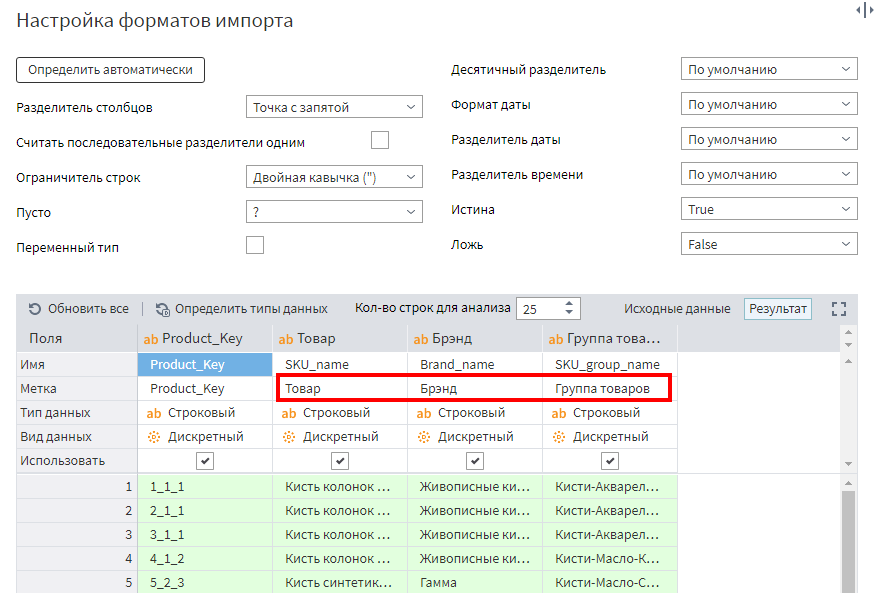
Описанный процесс надо повторить для файла Products.csv. Автоматического определения структуры файла будет достаточно. Однако для дальнейшего удобства задайте следующие метки полям:
Имена полей оставьте оригинальными. Все поля должны иметь текстовый тип.
Следующий шаг — добавление узлаимпорта из Excel и загрузка файла Clients.xlsx. Можно заметить, что начальный экран импорта отличается от такового для csv-файлов.
При импорте из Excel нужно указать лист или именованный диапазон, из которого будут взяты данные. Лист задается через порядковый номер (изменение порядка листов в файле сломает импорт) или имя (изменение имени листа в файле сломает импорт).

Настройку полей надо оставить как есть, только изменить метку поля Contractor_name на Юрлицо. Как итог, должно загружаться 3 строковых поля.

Сценарий будет выглядеть так:

Активируйте сценарий, чтобы все узлы стали зелеными. Кликните дважды ЛКМ по каждому выходному порту, чтобы посмотреть, какие данные были загружены.
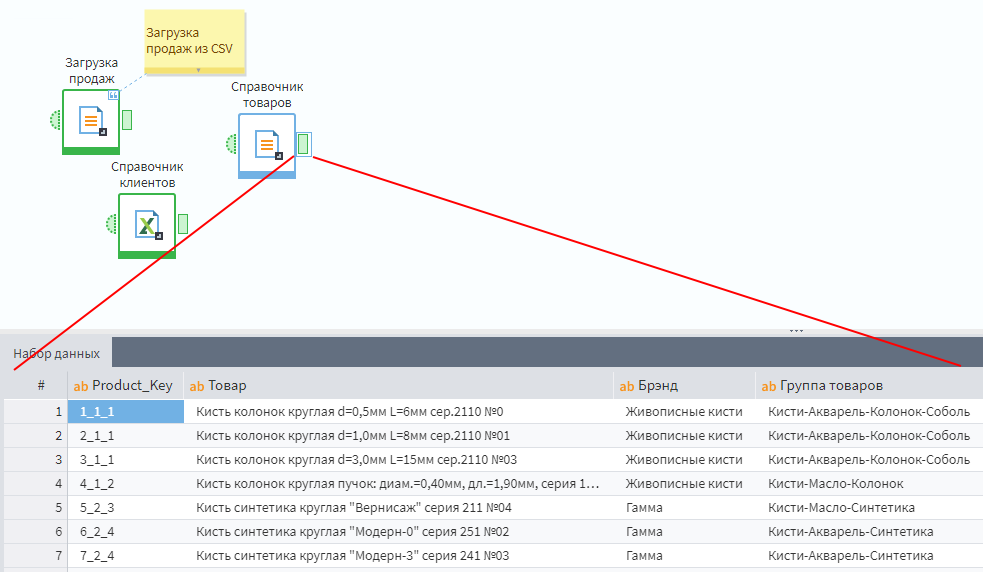
Для анализа данных из нескольких таблиц в Loginom предварительно их надо соединить в одну. По классике жанра в Loginom можно использовать соединение вида Join (добавление в таблицу столбцов другой таблицы на основе совпадающих ключевых значений) и соединение вида Union/Concatenate(добавление в таблицу строк другой таблицы).
Т.к. есть 1 таблица с данными и 2 справочника, будет правильным соединить данные со справочниками через Join. Для этого добавим узел Слияние из группы узлов Трансформация.

Узел Слияние всегда требует подать ему на вход 2 таблицы: основную и ту, которая будет присоединена. На верхний порт нужно подать данные по продажам, а на нижний — данные по товарам. Зайдите в настройки узла.
В мастере отображаются наборы полей 2-х таблиц. Чтобы Join сработал, нужно сопоставить ключевые поля. Свяжите эти 2 таблицы по полю Product_Key. В выпадающем списке сверху можно выбрать способ соединения таблиц. В данном случае требуетсяЛевое соединение.

Этот же процесс надо повторить для объединенной таблицы продаж и справочника товаров, сделав левое соединение по полю Client_ID. В результате сценарий должен выглядеть вот так:

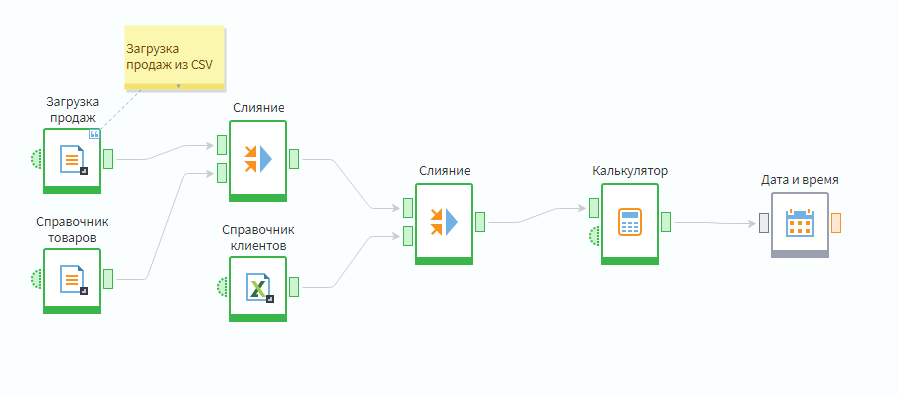
Далеко не всегда в источнике содержатся все необходимые для анализа атрибуты. Некоторые поля нужно создавать самостоятельно. Эту задачу решает узелКалькулятор из группы узлов Трансформация.
Надо добавить узел в сценарий и завести в него таблицу из второго Слияния. Далее войти в мастер настройки калькулятора. Мастер выглядит следующим образом.

Калькулятор состоит из 4-х областей.
В данных есть поля Сумма покупки и Себестоимость. Но нет поля Валовая прибыль.
Для его создания дважды кликните ЛКМ по заготовке нового поля, которое сейчас называется Expr1. Задайте этому полю имя Gross_profit и метку Валовая прибыль.

Создаваемое поле имеет ряд настроек.
Тип данных определяет, какие результаты и в каком формате сможет хранить в себе поле, например, в числовое поле нельзя записать текст. Хотя в самом выражении поля можно использовать функции, относящиеся к обработке строковых значений. Главное, чтобы на выходе получалось число. Вещественный тип нас полностью устроит.
Опция Промежуточное исключает это поле с выходного порта калькулятора. Ее нужно использовать, когда составляются сложные выражения. Чтобы не писать формулу на 1000 символов, часть этого выражения можно разместить в промежуточное поле. Ссылаясь в итоговой формуле на промежуточное поле, проще написать и понять формулу. При этом само промежуточное поле дальше калькулятора не выйдет и не будет засорять выходную таблицу.
Опция Кэширование сохраняет рассчитанные значения поля в оперативной памяти, а не рассчитывает их на лету при обращении из других узлов. Зачем это нужно?
Пропишите формулу как Сумма покупки + Себестоимость, дважды кликнув ЛКМ по именам этих полей в списке внизу для быстрой подстановки. Используйте кнопку предпросмотра, чтобы посмотреть результат.

Предпросмотр показывает 100 первых строк таблицы, включая вычисляемые поля, поля которые используются в вычислениях, переменные, которые используются в вычислениях. Если в выражении есть ошибка, пользователь получит предупреждение.

Выходите из калькулятора.
Последний штрих, прежде чем будет построен интерактивный отчет: в данных есть поле с датой продажи, но в отчетах наверняка потребуется группировка по неделям, месяцам и т.д.
Самый быстрый способ создать периоды от поля даты — использование узлаДата и время, из группы узлов Трансформация. Добавьте его в сценарий и заведите в него выход из Калькулятора.
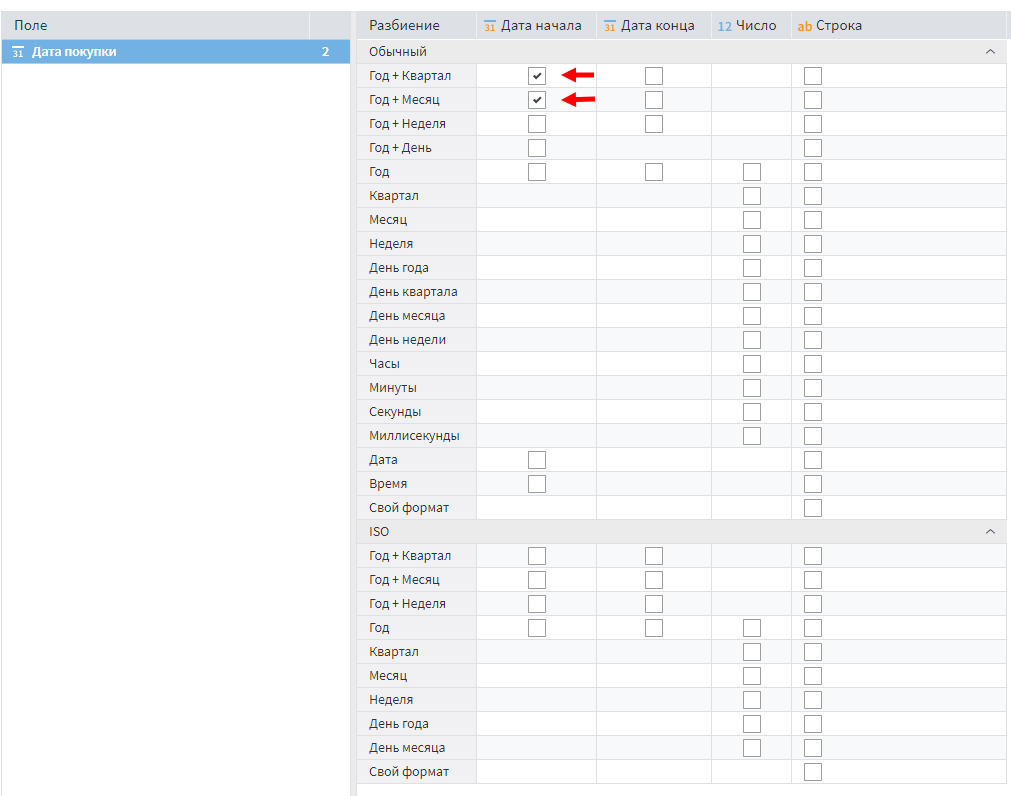
В настройках узла для каждого поля даты можно задать множество вариантов производных периодов. Для группировки по более крупным временным периодам рекомендуется выбирать опцию Дата начала нужного вам периода.
Это позволит группировать данные на нужном уровне и при этом сохранить числовую суть значений поля. Т.е. при сортировке апрель не будет идти перед декабрем, потому что первый начинается на «а».
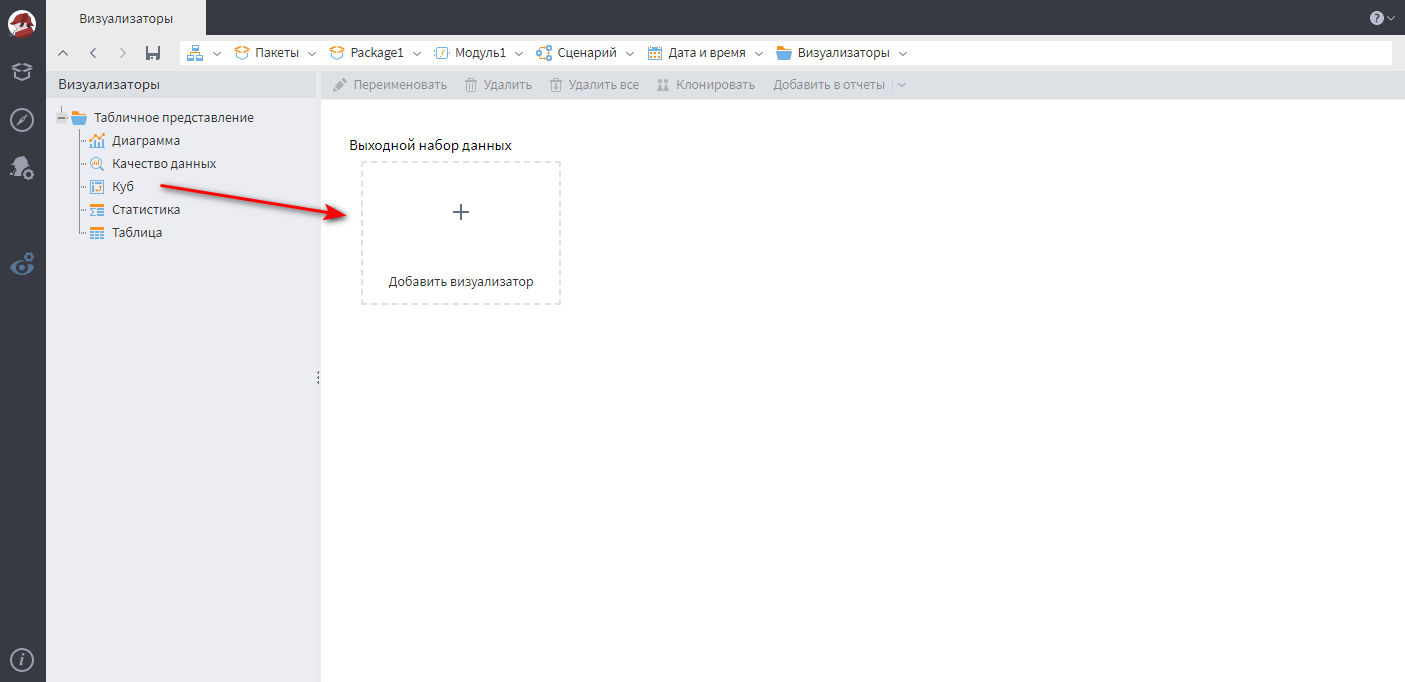
Теперь можно построить отчет. Для этого требуется настроить визуализатор для порта с итоговыми данными: кликните ЛКМ в центр узла Дата и время, а потом на пиктограмму глаза с шестеренкой.
Главный инструмент для построения интерактивных отчетов в Loginom — визуализатор Куб. Перетащите его в рабочую область и зайдите внутрь.
Для человека, хоть раз работавшего со сводными таблицами, все должно быть очень знакомо. Из списка полей слева перетащите месяц покупки в разрез строк, а поле Филиал — в столбцы.
Перетащите в центр таблицы поле Сумма покупки. Так добавляются поля для расчета показателей. При добавлении показателя (факта) надо выбрать способ агрегации. Можно отметить несколько вариантов сразу. По умолчанию выбирается Сумма. Раскройте его и дополнительно отметьте вариант Процент по горизонтали.

Размещенные в таблице данные можно визуализировать на диаграмме, если открыть ее, кликнув по кнопке Диаграмма в правом верхнем углу экрана.
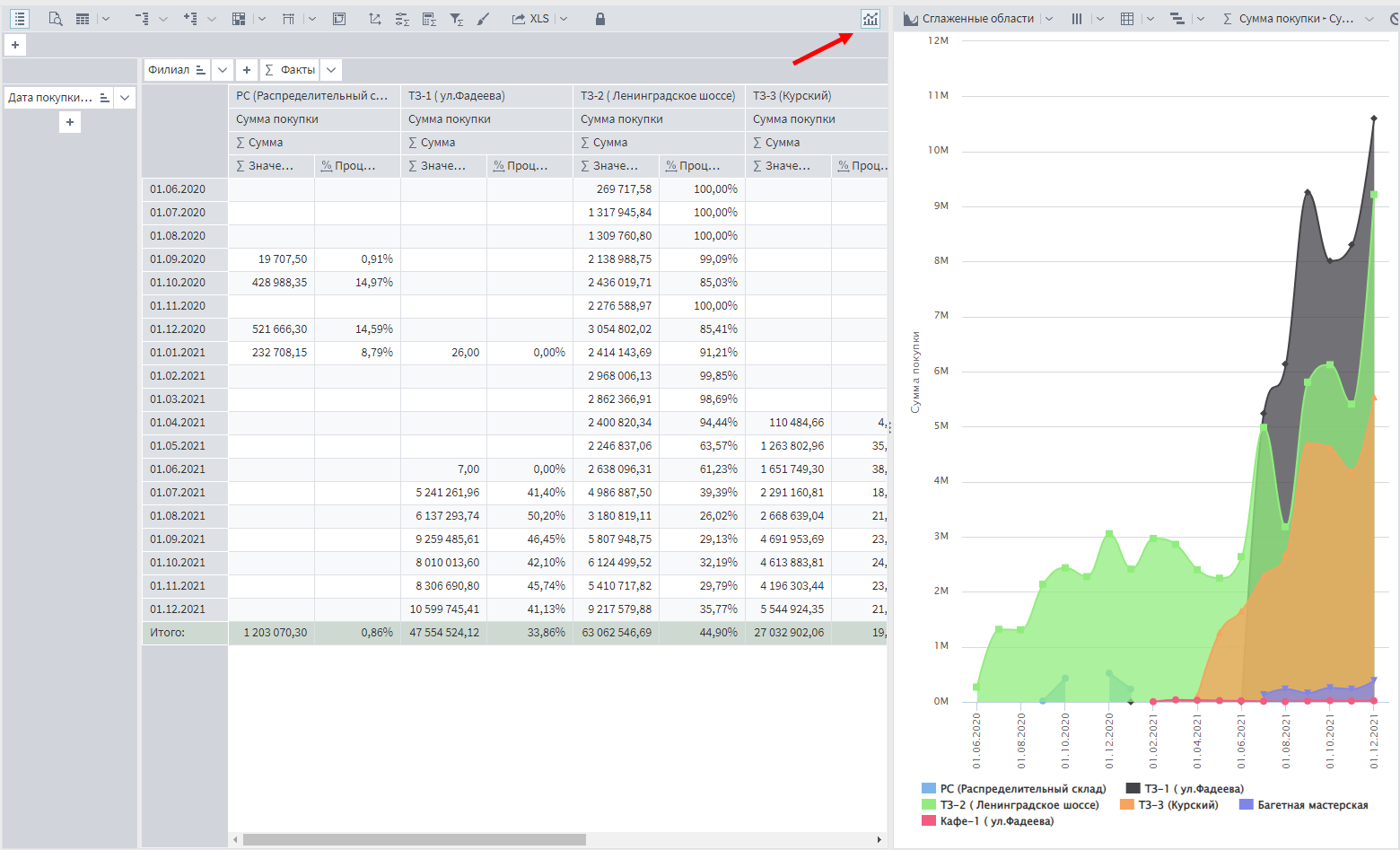
Несмотря на простой вид, у визуализатора Куб есть множество интересных функций, которые будут рассмотрены на будущих занятиях. Но если интересно узнать детали, можно посмотреть ролик.
Мы прошли базовый путь построения сводного отчета в Loginom. Но это не конечная цель, а скорее возможность покрутить исходные данные, которые будут использоваться для более сложной и интересной задачи — сегментации клиентской базы и поиска инсайтов. Ну и, конечно же, для исправления проблем в исходных данных.
zipДанные для практики. День 3.zip
Поэкспериментируйте с добавлением показателей и разрезов в Куб. Напишите в чат, какие проблемы в данных вы уже подметили.
Важно! Чтобы получить решение всех практических заданий марафона, нажмите на кнопку ниже.
Задачка со звездочкой. Создайте визуализатор вида Диаграмма, в котором отражался бы график продаж по месяцам. Учитывайте, что для этого визуализатора необходимо использовать массив данных, в котором одному месяцу будет соответствовать одно значение суммы. Попробуйте сформировать такой массив с помощью узла Группировка.
Бонусная задача. Добавьте в одну группу на панели отчетов визуализаторы Куб и Диаграмму, чтобы их можно было найти в одном пространстве, а не переключаться между узлами сценария.

Эксперт марафона: Евгений Стучалкин, руководитель и архитектор self-service решений BI2BUSINESS