
Пустые значения в данных могут создать серьезные трудности при обработке. Избежать неопределенности, возникающей при операциях с ними, позволяет использование значения NULL. Рассмотрим, как корректно обрабатывать наборы таких данных.
NULL представляет собой псевдозначение (маркер, флаг) в ячейке таблицы. Оно указывает на то, что ячейка является пустой, т.е. не содержит никакого значения, в том числе визуально не различаемого, типа пустой строки "" (строка нулевой длины).
Изначально понятие NULL было введено в язык SQL Эдгаром Коддом, автором правил, лежащих в основе построения реляционных баз данных. Четвертое правило гласит, что реляционная СУБД должна обеспечивать полную обработку неизвестных значений, для обозначения которых и было введено понятие NULL. Его поддержка, по мнению Кодда, является условием того, что база данных реляционная.
В рамках стандарта SQL значение NULL не эквивалентно ни значению 0, ни пустой строке "". Впрочем, некоторые СУБД, например, Oracle, отступают от этого правила, считая NULL и пустую строку эквивалентными. Это может вызывать определенное логическое противоречие, поскольку длина пустой строки равна 0, в то время как длина псевдозначения остается неопределенной.
Основной особенностью NULL является то, что оно не равно никакому значению, даже себе самому. Поэтому сравнение NULL с любым значением при использовании операторов больше, меньше, больше или равно, меньше или равно, равно, не равно лишено смысла, как сравнение с несуществующим значением.
Результатом такой операции будет не TRUE или FALSE, а третье логическое значение UNKNOWN. Таким образом, в реляционной модели, использующей NULL, имеет место трехзначная логика.
Тем не менее в реляционных СУБД можно проверить, является ли содержимое ячейки псевдозначением. Для этого используется функция IS NULL, которая возвращает TRUE, если ячейка содержит NULL, и FALSE в противном случае. Функция NOT NULL, соответственно, действует наоборот.
При агрегировании NULL игнорируется. И это вполне логично, поскольку если в агрегируемом поле появится хотя бы одно пустое значение, то результатом агрегации всегда будет NULL. Действительно, пусть требуется вычислить сумму значений по полю (4, 6, NULL, 3). Очевидно, что в этом случае получим 4 + 6 = 10, 10 + NULL = NULL, NULL + 3 = NULL. Поэтому при агрегации пустое значение не надо учитывать. Если для этого же набора потребуется вычислить среднее, то усреднение будет производиться по трем значениям.
Если агрегация применяется к полю, в котором содержится только псевдозначение, то результат будет NULL.
Еще одной операцией с NULL, результатом которой также будет NULL, является слияние содержимого в ячейках. Если в одной из ячеек содержится псевдозначение, то и результат будет пустым значением. Для предотвращения такой ситуации используют функцию CONCAT(), которая на вход получает список аргументов и заменяет NULL-значения пустыми строками.
Информация о различных операциях с NULL компактно представлена в таблице.
| Операция | Обозначение | Результат |
|---|---|---|
| Арифметические операции | +, -, *, / | NULL |
| Сравнение | =, <>, <, > | UNKNOWN |
| Конкатенация | CONCAT() | NULL игнорируется |
| Агрегирование | AGGREGATE() | NULL игнорируется |
| Подсчет числа строк | COUNT(*) | Возвращает число строк независимо от NULL |
| Подсчет числа строк | COUNT(FieldName) | Возвращает число строк в FieldName, в которых нет NULL |
| Является NULL | IS NULL | TRUE, FALSE |
| Не является NULL | IS NOT NULL | TRUE, FALSE |
Необходимость помечать NULL специфичным образом связана с тем, что работа с ним не укладывается в привычные правила. Например, если требуется просуммировать значения по полю, в котором есть пустая ячейка, то в конце концов будет выполнена операция суммирования, где один из операндов отсутствует, и в результате возникнет ошибка.
Если же в пустую ячейку поставить некоторый флаг или маркер отсутствия данных и определить набор правил, в соответствии с которыми NULL должен взаимодействовать с другими значениями, то ошибки можно будет избежать и завершить операцию хоть в каком-то виде. Соответственно, все операторы и функции работают с пустыми значениями, но результат может оказаться не таким, как пользователь ожидал бы, если бы значения NULL не было.
Может возникнуть вопрос: а почему нельзя использовать вместо отсутствующих значений 0 или пустую строку?
Дело в том, что 0 предполагает, что данные присутствуют, просто размер связанной с ними величины нулевой (например, нулевая сумма на счете или нулевой остаток товара на складе). Неопытные пользователи СУБД путают NULL с 0, что порождает ошибку, но ноль — это вполне конкретное число, с которым можно производить любые арифметические операции, кроме деления на него.
Пустая строка "" тоже не может служить признаком отсутствия данных. Она имеет длину (хоть и нулевую), чего отсутствующее значение иметь никак не может. С ней можно производить любые операции со строками и получить корректный результат. Пустая строка не идентична пустому значению.
Причины появления NULL обычно связаны с пропусками в данных, из которых наиболее распространенными являются:
При импорте данных и некоторых других операциях в Loginom могут появляться пустые ячейки. Результаты работы с ними могут показаться неожиданными. Это связано с тем, что логика обработки NULL специфичная.
Одной из проблем, связанных с NULL, является его визуализация. Действительно, в одних программах NULL может отображаться автоматически для каждой пустой ячейки. В других — только если пользователь активизирует соответствующую опцию. В третьих это вообще не предусмотрено. Таким образом, то, как визуализировать NULL, индивидуально для разных приложений, и пользователю обычно приходится разбираться с этим в каждом конкретном случае.
Например, в некоторых SQL-инструментах NULL автоматически отображается специальным образом.

Автоматическая установка NULL
В Loginom при быстром просмотре NULL в полях строкового типа отображается сразу. Это нужно для того, чтобы пользователь визуально различал поле с NULL и пустую строку "". Для того, чтобы увидеть пустые значения в полях всех типов необходимо зайти в визуализатор и выбрать таблицу.

Автоматическая установка NULL в Loginom
Затем нужно нажать на соответствующую кнопку на панели инструментов (выделена красным):

Включение NULL в Loginom
Кроме этого, увидеть наличие NULL в таблице и определить их количество можно с помощью визуализатора Статистика:
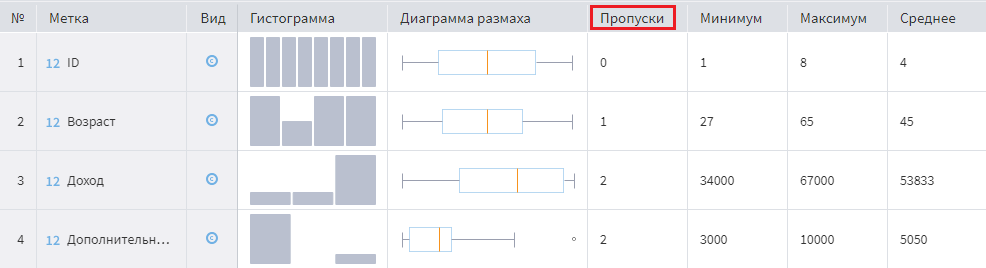
NULL в Статистике
Или с помощью визуализатора Качество данных:

NULL в обработчике Качество данных
В Loginom можно проверить, является ли значение в ячейке NULL-ом. Для этого используется функция IsNull(), которая возвращает TRUE, если ячейка содержит NULL, и FALSE в противном случае.
Зададим в Калькуляторе следующее выражение.
")
Применение функции IsNull()
Тогда результат будет следующим:
")
Результат функции IsNull()
Функцию можно задавать не только для отдельных полей, но и для выражений или результатов вычислений.
При выполнении арифметических операций с полями, содержащими NULL-значения, надо проявлять осторожность, чтобы не получить неожиданные результаты. Рассмотрим методы работы с такими данными в Loginom.
В таблицах присутствуют ячейки с NULL. Вычислим с помощью обработчика Калькулятор сумму столбцов Доход, Дополнительный доход и посмотрим, что даст суммирование с NULL. Результат представлен в следующей таблице:

Суммирование
Все суммы ячеек с NULL также дали результат NULL, поэтому в новом поле пустых значений стало больше. Такой накопительный эффект ставит под вопрос возможность суммировать ячейки с NULL-значениями.
Тем не менее решить данную проблему можно с использованием функции NVL(). Она позволяет вернуть значение выражения, если оно не является NULL, и задать собственное в противном случае.
Например, если для ранее рассмотренного набора данных в Калькуляторе применить следующее выражение.
")
Применение функции NVL()
Будет получен следующий результат.
")
Результат применения функции NVL()
Таким образом, вместо NULL будут значения, которые реально соответствуют общему доходу. Идея заключается в том, что если нет информации об уровне основного или дополнительного дохода, считаем его как нулевой. Это позволяет избежать накопления чрезмерно большого числа пропусков в результирующем поле.
Еще одной часто используемой операцией при работе с данными является фильтрация. Для этого воспользуемся компонентом Фильтр строк. Возникает вопрос: а как будут обрабатываться NULL-значения при проверке условий фильтрации? Значения NULL будут считаться удовлетворяющими или не удовлетворяющими условию фильтрации?
Для ранее рассмотренного набора данных проведем фильтрацию по полю «Возраст», в соответствии с условием, заданным на рисунке:

Условие фильтрации
В соответствии с заданным условием будут сформированы два подмножества записей: одно будет содержать записи, которые удовлетворяют условию фильтрации (возраст больше 45), а другое — не удовлетворяют (возраст меньше или равен 45).

Удовлетворяют условию

Не удовлетворяют условию
Таким образом, в приведенном примере NULL-значения, находящиеся в поле, по которому производится фильтрация, включаются в подмножество записей, не удовлетворяющее условию фильтра. Это связано с тем, что NULL не равно (следовательно, не может быть больше или меньше) никакому значению.
Это может порождать странные на первый взгляд ситуации. Если в фильтре изменить знак в условии на противоположный, то подмножества записей, удовлетворяющих и не удовлетворяющих условию, поменяются местами. Однако, это справедливо только для записей, где в поле, по которому производится фильтрация, нет NULL. Такие записи не будут реагировать на изменения условий фильтрации, что может запутать неопытного аналитика.
Для иллюстрации сказанного изменим условие фильтрации из предыдущего примера на противоположное:

Измененное условие фильтрации
Тогда подмножества записей, удовлетворяющее условию и нет будут выглядеть так:

Подмножество, удовлетворяющее измененному условию

Не удовлетворяющее
Как видно, записи с NULL остались в том же подмножестве, что и до изменения условий фильтрации, что подтверждает сказанное.
Для получения набора данных, в которых останутся ячейки без псевдозначений, можно воспользоваться следующим условием.

Фильтрация данных
В результате останутся данные, где нет NULL-значений.

Данные без NULL-значений
Следующий компонент, который обрабатывает пустые значения специфичных образом, — сортировка. Отсортируем данные по полю Доход.

Настройка сортировки
Получим следующий результат:

Сортировка по возрастанию
При сортировке по возрастанию значения NULL располагаются в начале перед всеми остальными значениями. Псевдозначения обычно рассматриваются как минимальные (или «меньше» всех других). Соответственно, при сортировке по убыванию значения NULL будут располагаться в конце списка после всех прочих значений.
В процессе обработки данных возникают ситуации, когда в ячейках оказываются экстремальные или фиктивные значения, с которыми нецелесообразно работать ни в каком виде, т.е. может сработать правило: лучше обрабатывать ячейку как пустую, чем с тем, что в ней содержится.
Рассмотрим на примере.
")
Пример для функции Null()
В приведенной таблице в поле возраст есть два значения 99, которые, скорее всего, являются фиктивными, т.е. были поставлены оператором вместо отсутствующего. Чтобы заменить их на NULL, как показано на предыдущем рисунке для вычисляемого поля Verification (Проверка возраста), используем выражение в Калькуляторе:
")
Выражение для функции Null()
Получим, что вместо фиктивных значений будут пропуски, которые можно восстановить, используя соответствующие методы очистки данных.
Результат экспорта таблиц, в которых присутствуют значения NULL, зависит от того, куда выгружаются данные.
Например, при экспорте таблицы из Loginom в Excel NULL в целевой таблице перестает отображаться.

Выгрузка данных из Loginom в Excel
Это связано с тем, что Excel не является СУБД, и NULL используется там в ином контексте. Пустые ячейки в Excel тоже присутствуют, и их использование в формулах приводит к неопределенным результатам. В этом случае NULL отображается в ячейке, где содержится формула. Поэтому в Excel NULL используется не как флаг отсутствия данных в ячейке, а как индикатор неопределенного значения формулы, в которой один из операндов является пустой ячейкой.
В отличии от Excel, при экспорте в csv-файл пользователю явно предлагается выбрать вид индикатора, указывающего на пустую ячейку. Это выглядит следующим образом:

Выгрузка данных из Loginom в текстовый файл
На рисунке видно, что можно задать три варианта индикатора «NULL», «null» или «?». При этом следует понимать, что поскольку текстовый файл не является файлом базы данных, NULL теряет смысл, в котором он понимается в SQL. Псевдозначения и правила работы с ними, не регламентируются стандартом SQL, как в случае СУБД, а определяются разработчиком конкретного приложения.
Правила работы с NULL-значениями зависят от используемой программы, поэтому поведение других систем может отличаться от логики, реализованной Loginom. Для корректной обработки рекомендуется обращаться к официальной документации. Использование NULL-значений хотя и позволяет в определенной степени решить проблему пропусков в данных, тем не менее требует внимания и изучения того, как с этим значением работают те или иные приложения.
Другие материалы по теме:





